这一层讨论如何约束 Agent 行为、确保安全性并建立问责机制。LLM Agent 如今已能执行 shell 命令、提交代码以及调用第三方 API。对于生产环境而言,一个核心问题是:Agent 应在什么约束条件下行动,当这些约束失效时由谁承担责任。治理拥有独立的工具生态系统,包括权限引擎、策略语言、审计流水线和网关控制。

1. 权限模型与身份管理
权限模型与身份管理解决的是“智能体能访问哪些资源”这一核心问题。由于智能体执行的任务通常是由自然语言定义的,在部署时往往难以预知其所需的工具集,这使得传统的访问控制模型(如 RBAC 或 ABAC)面临挑战。论文基于粒度的视角展开论述,从部署时固定的静态边界,到每次工具调用时评估的上下文策略,再到多智能体间的访问策略,等等。
- 静态权限边界 (Static Boundaries):
- 做法:在部署前预定义固定的权限范围。例如,Codex 将 shell 命令限制在特定沙箱内,Gemini CLI 则结合工作区范围的文件访问和命令黑白名单。类似地,可以重点关注 Claude Code 的权限系统设计。
- 优缺点:易于审计和检查,但缺乏针对具体任务的灵活性,无法表达“任务特定的意图”。
- 上下文相关的特权控制 (Context-dependent Control):
- Progent:引入了一种DSL,在每次工具调用前评估谓词(包含工具名、参数和环境状态),实现最小特权策略。
- Conseca:从受信任的上下文中生成任务特定的策略,并由独立的确定性检查器强制执行。这种“策略生成与强制执行分离”的设计对于保证系统的可审计性至关重要。
- 身份管理与智能体间的访问控制:在多智能体协作或跨系统交互中,建立“谁在请求权限”的身份基石是安全的前提。
2. 生命周期钩子
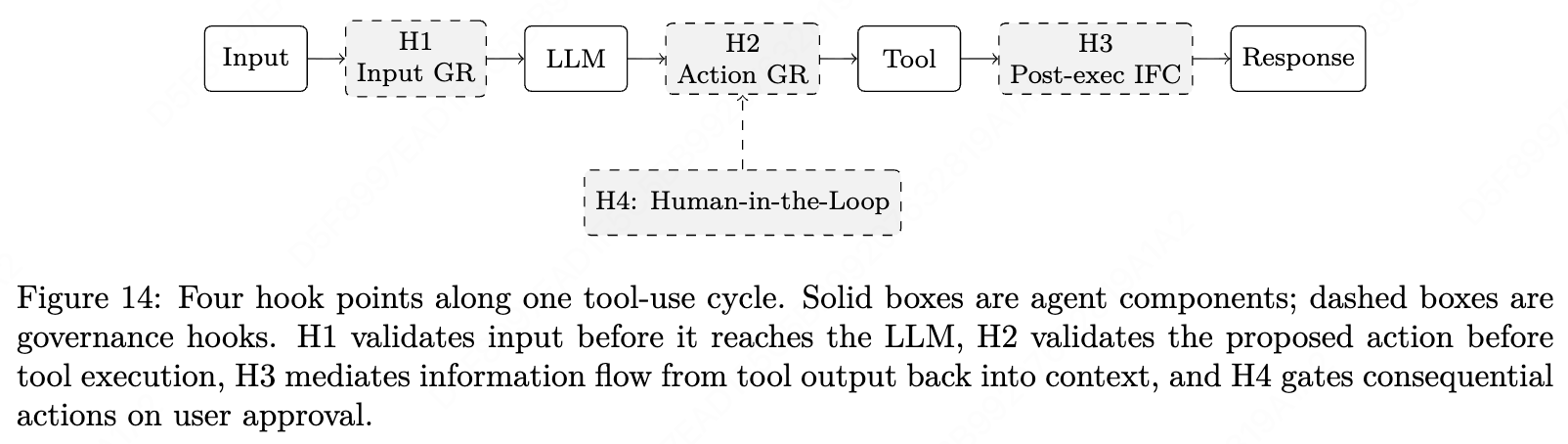
如果说权限模型定义了“什么是允许的”,那么生命周期钩子则定义了“什么时候触发策略检查”。通过在 Agent Loop 的特定阶段插入钩子,开发者可以在不修改模型核心推理逻辑的情况下,注入安全与合规性逻辑。生命周期钩子的治理作用主要体现在以下四个关键点(见图 14):
- Pre-execution hooks: input guardrails.
- 治理作用: 在数据抵达大模型之前对其进行拦截和验证。
- 具体功能: 主要用于防御提示词注入攻击 (Prompt Injection)。系统会部署专门的分类器(如 PromptShield 或 DataSentinel)来扫描用户输入或从外部检索的内容,识别其中是否隐藏了恶意载荷。这确保了模型接收到的指令是受信任且符合预期的。
- Pre-invocation hooks: output guardrails and action validation.
- 治理作用: 在智能体执行工具调用前进行最后的合规性审查。
- 具体功能:
- 谓词验证: 使用如 ShieldAgent 这种系统,将安全策略表达为可验证的谓词,检查智能体生成的每个工具调用参数是否越界。
- 控制流保护: 在多智能体系统中,钩子(如 ControlValve)可以监控智能体之间的跳转,防止因“控制流劫持”导致智能体绕过安全节点直接执行高危操作。
- Post-execution hooks: information flow control and taint tracking.
- 治理作用: 监控工具执行返回的结果,在这些数据进入 LLM 上下文之前进行处理。
- 具体功能: 为了防止不安全的数据污染模型的后续决策,一些高级系统(如 CaMeL)会通过钩子实现污点追踪(Taint Tracking)。它为每个数据值打上标签,区分“受信任的用户输入”和“不可信的网页检索内容”,确保不受信任的数据不会影响关键的控制决策。
- Human-in-the-Loop hooks. // 这部分的设计还是可以看 Claude Code 的权限系统设计
- 治理作用: 将人类作为最高层级的决策者,对具有严重后果的操作进行人工审批。
- 具体功能: 设计一个有效的人机协作钩子需要平衡三个维度的工程选择:
- 验证范围 (Validation Scope):明确定义哪些特定的工具调用或操作序列需要触发人工审核。
- 警报丰富度 (Alert Richness):在申请审批时,向用户展示多少上下文信息(如智能体的意图、即将执行的具体命令、可能产生的影响)。这对于防止用户由于信息不足而产生的误判至关重要。
- 复现策略 (Recurrence Policy): 决定审批的持久性,例如是“仅允许此次操作(Allow-once)”还是“在此会话中永久允许此类操作(Allow-always)”。
- 治理权衡: Human-in-the-Loop hooks 涉及到 “Liveness vs. Safety” 的权衡。如果钩子设置得过于频繁,用户可能会产生习惯性反应,不经思考地点击“同意”,从而使安全机制失效。合理的钩子设计能减少 84% 的不必要提示,防止用户产生“审批疲劳”或“条件反射式同意”,提升治理的有效性。
3. 组件加固
组件加固的核心逻辑是通过增强智能体系统中单个组件(如模型和工具)的安全性,从源头减少恶意输入触发下游治理钩子的概率。具体而言,组件加固主要通过以下三个层面来增强系统安全性:
-
模型加固 (Model Hardening):模型加固旨在解决大模型无法区分“高优先级指令”和“低优先级数据”的根本缺陷,从而防御提示词注入攻击。
- 指令层级化 (Instruction Hierarchy): 通过训练让模型学会优先执行系统提示词(特权指令),而忽略或拒绝与之冲突的用户消息或工具输出。
- 偏好优化 (SecAlign): 利用偏好优化技术(如针对提示词注入样本进行对抗训练),使模型在推理时能够自主识别并拒绝恶意指令。
-
运行时分类器加固 (Classifier-based Runtime Hardening):这种方法不需要修改核心模型,而是通过在模型边界部署辅助分类器来筛选输入和输出。
- 安全分类 (如 Llama Guard): 使用专门的小模型根据预设的安全分类法对用户提示和助手响应进行实时扫描。
- 灵活性与复用性: 这种方式的优势在于无需重新训练智能体模型即可更新安全规则,且同一套检测器可以复用到不同的 LLM 后端。
-
工具与协议加固 (Tool and Protocol Hardening):针对智能体调用的外部工具和通信协议进行安全增强,防止供应链攻击和越权操作。
- 加密签名与版本控制(ETDI):对工具定义(如 MCP 工具)进行加密签名。这可以防止“地毯式撤回攻击(Rug-pull attacks)”,即防止一个原本已被批准的工具在后台被秘密更新为恶意版本。
- 事务性执行语义(SAFEFLOW):在多智能体系统中引入协议级强制执行,支持事务回滚。如果检测到违规的工具调用或消息,系统可以将状态回滚到安全点,防止错误传播。
加固技术旨在让模型和工具本身更难被攻破,而钩子则是在运行时对残留风险进行拦截,两者共同构成了系统的深度防御 (Defense-in-depth) 体系。
4. 声明式章程
声明式宪法 (Declarative Constitutions) 的核心作用是将智能体的行为准则、合规性策略和安全约束从硬编码的应用程序逻辑中剥离出来,转化为一种外化的、机器可读的配置规范。
声明式宪法的作用体现在以下几个关键方面:
-
提升治理的透明度与可审计性。将治理逻辑硬编码在程序中会使其变得不透明且难以审计。通过声明式配置文件(通常为 YAML 格式),这些规则变成了可以被人类和机器同时阅读的“宪法”,从而:
- 分离治理意图与执行逻辑:让开发者以外的利益相关者(如安全团队或合规官)能够直接审查和修改政策,而无需触碰底层代码。
- 支持版本控制:宪法文件可以像代码一样进行版本管理、差分对比和回滚,确保政策变更的记录清晰可查。
-
区分训练时对齐与部署时约束。论文对比了两种不同的实现路径:
- 训练时宪法(如 Anthropic 的 Constitutional AI):在模型对齐和后训练阶段注入安全、伦理和合规准则。这种方式塑造了模型的底层行为偏好,但在部署后难以修改,且容易被对抗性攻击绕过。
- 部署时宪法(如 AutoHarness):作为一种Harness层检查运行,它定义了风险分类、工具调用黑白名单、Token 预算等具体限制。它允许在不重新训练模型的情况下更新策略,提供了比概率性对齐更强的确定性控制。
-
实现结构化的策略表达 (DSL)。声明式宪法不仅限于静态的 YAML 列表,还可以演进为更具表达力的可编程策略语言:
- 动态谓词 (Progent):支持布尔谓词和量词,能够根据运行时状态动态决定是否允许某项操作。
- 形式化约束 (Formal-LLM):利用下推自动机(Pushdown Automata)对智能体的计划路径进行建模,强制执行特定的操作顺序或禁止危险的工具组合。
- 意图验证 (VeriSafeAgent):将用户意图形式化为 UI 状态转换的 DSL,确保智能体的行为与用户目标保持一致。
5. 审计基础设施
审计基础设施的核心作用是为智能体行为建立问责机制(Accountability)。它不仅记录智能体“做了什么”,还记录“为什么这么做”以及是否遵守了预设的治理策略。
提供结构化的证据记录。审计基础设施负责生成可回放、可追溯的执行记录。一个完整的审计记录通常需要包含以下关键要素:
- 身份与溯源: 追踪标识符(Trace ID)和主体身份(Principal Identity)。
- 行动细节: 具体的工具调用(Tool Invocation)及其执行结果。
- 决策依据: 策略决策及其版本(Policy Decision & Version),用于解释为何允许或拒绝某项操作。
- 成本与完整性: 资源消耗成本以及用于防篡改的完整性哈希(Integrity Hash)。
支持事后调查与合规性审查。通过记录详尽的运行日志,审计基础设施为以下场景提供了必要支持:
- 取证分析: 在系统出现安全故障或非预期行为时,支持开发者进行事后调查(Post-hoc Investigation)。
- 监管合规: 满足行业对自动化系统操作的合规性(Compliance)审计要求。
驱动持续的策略优化。审计不仅仅是记录,它还是治理闭环中的重要反馈源:
- 策略改进: 通过分析审计记录,开发者可以发现现有的治理约束是“太松”还是“太紧”,从而进行持续的政策精炼(Policy Refinement)。
- 回归系统: 审计记录可以转化为回归测试用例,确保治理规则的更新不会引发新的风险。
实现多层级的异常检测。审计基础设施为自动化的风险识别提供了数据底座:
- 单步操作监测: 实时拦截风险操作(如输入/输出护栏)。
- 轨迹级检测: 通过对审计日志进行异步分析,识别那些分布在多个看似无害的动作中的复杂攻击(例如通过每分钟读取一个文件来实现的缓慢数据外泄)。
成本与资源治理。在长程任务中,审计基础设施还承担了资源监控的职责,防止智能体陷入死循环导致 API 预算耗尽。例如,某些系统会通过审计日志实时追踪 Token 消耗,并根据声明式宪法中定义的预算限制强制终止任务。
审计基础设施将治理从一种“实时拦截”扩展到了“全生命周期的透明度管理”。它确保了即便智能体具备高度的自主性,其每一个决策和动作也都是可解释、可审计且受控的,这是将 LLM 智能体大规模部署到严肃工业生产环境的先决条件。