
1. Harness Evaluation as a Task-to-Feedback Lifecycle
首先,我们需要打破传统评估的固有认知,即评估分数应当被视为“Model-Harness 对”的属性,而不仅仅是模型本身的能力体现。这对应于本文贯穿始终的“绑定约束理论”,即任务执行的可靠性很大程度上取决于模型之外的 Harness 基础设施(Agent = Model + Harness)。因此,这要求在评估协议中,要么保持 Harness 不变,对比模型;要么保持模型不变,将不同的 Harness 配置作为显式的实验因子进行测试。
此外,Harness 评估与传统 LLM 评估也存在根本差异。传统 LLM 评估通常针对固定的输入,对输出进行评分(如 MMLU);Harness 评估衡量的则是一个执行集(Execution Episode,即 Agent 与环境交互的一个完整周期)——任务被锚定于某个环境中,智能体在其中与工具、状态进行多轮交互,评估者需要判断最终结果以及达成结果的路径(轨迹)。
为此,作者提出了一个核心概念,将 Harness 评估视为一个“从任务到反馈的生命周期(Task-to-Feedback Lifecycle)”。下图展示了 task-to-feedback lifecycle 的五个阶段。
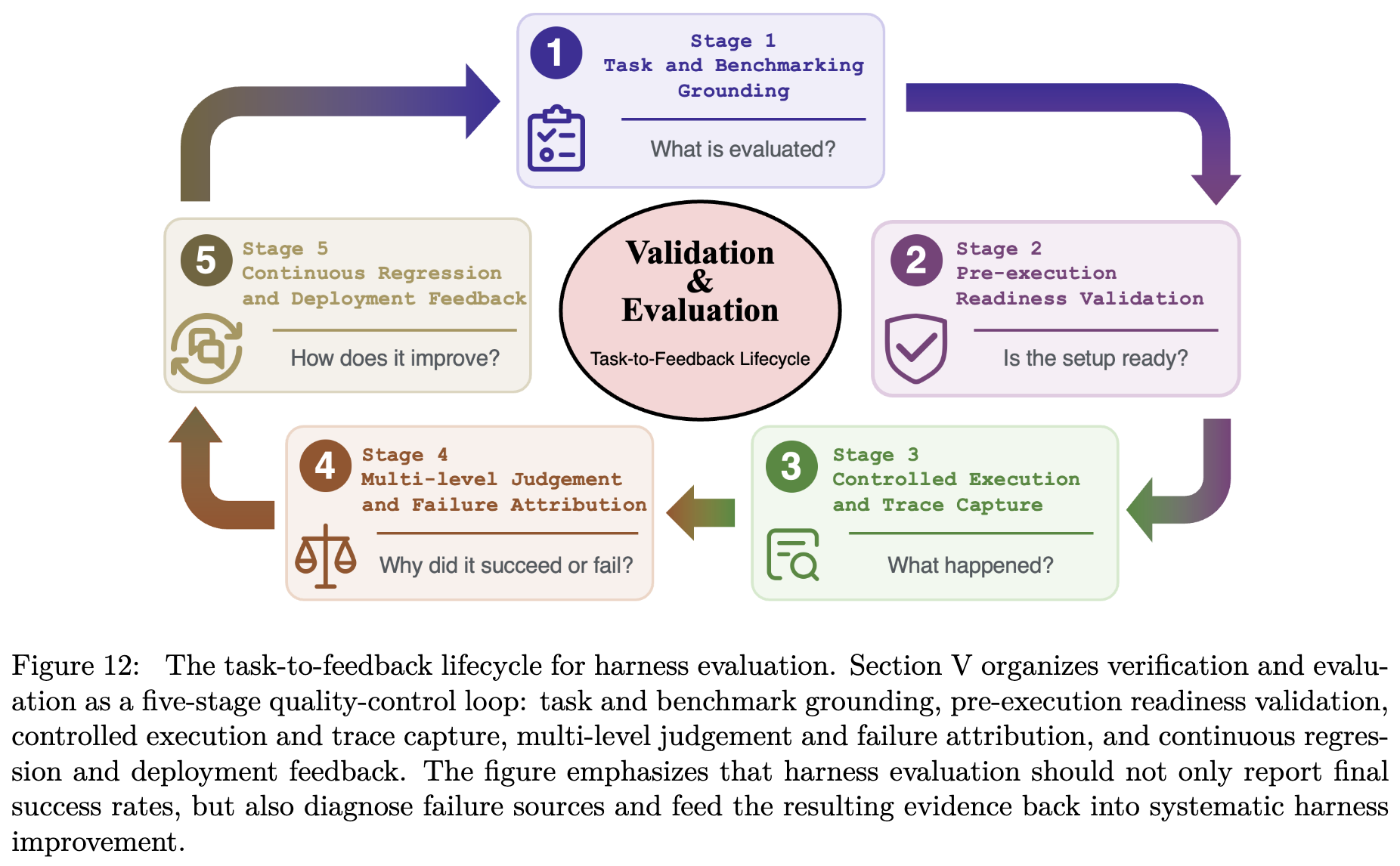
作者引入生命周期视角的一个重要动机在于,评估基础设施的噪声可能被误当作模型的失败。 在复杂的智能体运行中,失败的原因可能多种多样,如工具损坏、上下文过时、沙箱未重置、测试用例不稳定或评估器本身出现偏差。 因此,评估不能仅仅给出一个最终分数,而必须将 Agent 行为转化为结构化的判断、失败归因和回归反馈。
task-to-feedback lifecycle 的五个阶段涵盖了从任务定义到系统改进的全过程,具体包括:
- 阶段 1:任务与基准锚定 (Task and Benchmark Grounding)
- 核心问题:评估什么?
- 内容:定义环境状态、可用工具、允许的操作、约束条件和成功准则。
- 阶段 2:执行前就绪验证 (Pre-execution Readiness Validation)
- 核心问题:环境设置准备好了吗?
- 内容:在运行前检查沙箱、依赖项、工具、权限策略和预算是否正确初始化,确保环境的公平性和可重复性。
- 阶段 3:受控执行与轨迹捕获 (Controlled Execution and Trace Capture)
- 核心问题:发生了什么?
- 内容:在可重复的条件下运行智能体,记录模型输出、工具调用、状态变化、错误、成本和延迟,将运行过程转化为可诊断的证据。
- 阶段 4:多级判断与失败归因 (Multi-level Judgement and Failure Attribution)
- 核心问题:为什么成功或失败?
- 内容:不仅看结果是否正确(Outcome),还看路径是否合规高效(Trajectory),并将失败具体归因到模型、工具接口或上下文管理等具体的 Harness 组件上。
- 阶段 5:持续回归与部署反馈 (Continuous Regression and Deployment Feedback)
- 核心问题:如何改进?
- 内容:将评估诊断结果转化为回归测试和工程反馈,驱动下一轮的 Harness 迭代和优化。
2. Stage 1 - Task and Benchmark Grounding
阶段 1 的核心任务是回答“到底在评估什么”这一基本问题。在 Harness Engineering 语境下,一个任务不仅仅是一段提示词,而必须包含以下要素:
- 环境状态(Environment state): 任务发生的具体场景(如一个具体的 GitHub 仓库镜像或一个虚拟机状态)。
- 可用的工具以及允许执行的操作(Available tools & Allowed actions): 智能体被允许调用的 API 或执行的命令。
- 约束条件(Constraints): 执行过程中的限制,如时间预算、Token 限制或安全边界。
- 终止条件与成功准则(Termination conditions & Success criteria): 明确定义什么样的情况下会终止任务,以及如何判定任务是否执行成功。
论文将目前的任务分为三个主要领域:
- 软件工程与终端任务:
- 代表性基准: SWE-bench 和 Terminal-Bench。
- 特点: 强调可执行的验证。例如,SWE-bench 将任务锚定在真实的 GitHub Issue 中,通过运行测试用例来验证生成的补丁是否解决了问题。
- 关键洞察: 强有力的结果校验器需要精确的任务落地,如果环境状态或依赖项未对齐,评估结果将不可靠。
- Web, Browser, and Computer-Use Tasks:
- 代表性基准:WebArena、VisualWebArena、OSWorld。
- 特点:任务锚定在交互式环境中,成功被定义为浏览器或操作系统状态的改变(如点击、输入、文件操作)。
- 关键洞察:评估问题本质上也是一个环境设计问题。Harness 必须提供真实的界面并暴露适当的观测值,这直接连接了“执行环境”层与“评估”层。
- 跨领域与企业工作流任务:
- 代表性基准: AgentBench、GAIA、WorkArena。
- 特点:测试智能体在异构工具和复杂流程中的泛化能力。
- 关键洞察:衡量智能体能否在复杂的软件系统中导航,而不仅仅是回答孤立的问题。
总结来说,阶段 1 的目标是构建一个物理上可运行、逻辑上可验证的实验场。它是后续所有评估步骤(如轨迹捕获和失败归因)得以进行的先决条件。没有良好的任务锚定,后续的分数将无法解释。只有精确定义了任务、环境和成功判定条件等要素,测试才具有可重复性。
3. Stage 2 - Pre-execution Readiness Validation
阶段 2 关注的核心问题是:“环境准备好了吗?评估是否可以公平且可复现地运行?”。这一阶段在许多基准测试中往往是“隐形”的,但它对于确保评估的公平性、可重复性以及失败归因的准确性至关重要。
这一阶段的核心目标是消除“评估基础设施噪声”,防止因环境故障、设置不统一等因素而被误判为是智能体的能力不足。如果没有这一层验证,一个失败的运行结果可能并不是因为模型问题导致的,而是由于工具损坏、依赖缺失或沙箱未重置等“噪声”引起的。
就绪验证涵盖了从物理环境到语义权限的多个层面:
- 环境与沙箱就绪 (Environment and Sandbox Readiness):
- 验证内容:确保沙箱(如 Docker 容器、虚拟机或浏览器配置)已重置到预定义的基准状态,且所有必要的软件依赖项都已正确安装。
- 系统示例:Repo2Run 通过自动化构建可执行的 Docker 环境来解决依赖设置问题;SWE-bench 和 OSWorld 则依赖于精确的环境快照来保证测试的起点一致。
- 工具、上下文与权限就绪 (Tool, Context, and Permission Readiness):
- 工具:验证 API、MCP 服务器和 shell 命令是否可用,且其描述与基准规范一致。
- 上下文:检查对话历史、记忆存储或检索文档是否已清空,防止“状态泄露”让模型在不知不觉中利用了先前的运行信息。
- 权限:验证网络访问规则和凭证是否符合基准限制。如果权限太严,智能体会因为无法操作而失败;如果太松,则可能发生利用漏洞的非预期成功。
- 验证器与评分器就绪 (Evaluator and Grader Readiness):
- 验证内容:在任务开始前检查评分器本身。例如,确定性测试脚本是否存在不稳定性;如果使用 LLM-as-Judge,则需要确认评分标准已正确校准且模型版本已固定。
总结来说,阶段 2 是对“实验仪器”的校准。它将评估环境从一个不可见的黑盒,转变为一个可观测、可记录且可审计的受控变量。一个严谨的评估 Harness 应该将这些配置(包括工具注册表、上下文策略、权限策略、预算和超时等)作为评估元数据(Evaluation Metadata)进行记录,只有通过了就绪验证,后续捕获的执行轨迹(阶段 3)才具有真正的诊断价值。
4. Stage 3 - Controlled Execution and Trace Capture
阶段 3 的核心任务是在受控且可重复的条件下运行智能体,并将其所有的交互行为转化为可供分析的证据。
首先,我们需要明确一个基本概念,即 Harness 评估的基本单位是什么?作者将其定义为 Controlled Rollout。 一个 Rollout 包含任务定义、模型配置、Harness配置、动作序列、中间观测值、最终环境状态以及评分结果。Controlled 指的是为了确保评估的严谨性,必须固定所有非预期的变量,包括环境初始状态、工具可用性、Token 预算、权限策略以及评估器版本等。如果系统中仍存在不可避免的随机性,则需要通过多次重复回放来观察其方差,而不是仅依赖单一的分数。
此外,评估不应仅仅是“通过”或“失败”的二元判断,而必须是**轨迹原生(trace-native)**的。如何理解 trace-native ?本质上,**在 Harness 工程中,轨迹不再是辅助调试的副产品,而是主要的评估数据来源。**一个完整的轨迹应捕获模型输出、工具调用及其结果、环境状态变化、上下文快照、错误重试、Token 消耗及延迟等。只有通过轨迹,系统才能识别出一些虽然结果正确但过程不可靠的情况,例如,利用基准测试漏洞(Benchmark Exploitation)、调用了过多的工具或违反了安全权限等情况。
最后,优秀的智能体不仅要能完成任务,还要尽可能高效地完成。作者定义了**”Success-Cost-Latency“**的多维衡量标准 ,即评估不应该只关注任务成功率,而应考虑成功率、成本和速度三者之间的权衡。
总结来说,阶段 3 的目标是实现执行过程的可观测性与可重复性。它通过受控回放确保了评估的公平性,通过轨迹捕获实现了从“黑盒评分”到“因果诊断”的跨越。对于长周期运行的智能体,这一阶段提供的信息流是整个 Harness 系统持续优化的核心反馈源。
5. Stage 4 - Multi-level Judgement and Failure Attribution
阶段 4 不仅关注智能体“是否成功”,更核心的目标是将执行证据转化为可操作的工程诊断,从而区分究竟是模型不足还是Harness缺陷。
论文对智能体的评估从三个层面展开,以克服单一“成功率”指标的不足:
- 结果评估(Outcome-level):
- 核心指标:任务最终目标是否达成(如:单元测试是否通过、PR 是否被合并、网页表单是否提交成功)。
- 局限性:虽然易于量化,但它会掩盖执行过程中的鲁棒性、安全性或效率问题。
- 轨迹评估(Trajectory-level):
-
核心指标:智能体选择工具的准确性、行动顺序的逻辑性、是否规避了冗余调用、是否遵守了权限边界以及错误恢复的效率。
-
工程意义:即使结果正确,如果轨迹显示智能体浪费了大量 Token 或通过非法手段绕过了安全限制,该运行也应被判定为不可靠。Anthropic 的实践中,评估者会通过“Sprint Contracts”在执行前定义“完成”的标准,从而在执行中对轨迹进行精细化审查。
Before each sprint, the generator and evaluator negotiated a sprint contract: agreeing on what “done” looked like for that chunk of work before any code was written. This existed because the product spec was intentionally high-level, and I wanted a step to bridge the gap between user stories and testable implementation. The generator proposed what it would build and how success would be verified, and the evaluator reviewed that proposal to make sure the generator was building the right thing. The two iterated until they agreed.
-
- 评估器本身评估(Evaluator-level):
- 核心指标:评估器本身(无论是确定性脚本还是 LLM-as-Judge)是否可信。
- 风险防范:必须识别评估器中的偏见(如 LLM 倾向于给模型生成的文本打高分)或测试脚本的不稳定性,防止“评估噪声”被误认为是智能体的失败。
在上述三层评估中,最重要的是轨迹评估,这是 Harness 工程的精髓。通过对轨迹的分析,进行失败归因,将失败精准地归因到 ETCLOVG 架构的具体层级,进而优化相应的 Harness 组件:
- 归因至工具层:如果智能体选错了工具或无法处理工具返回的 JSON,说明工具接口或描述需要优化。
- 归因至上下文层:如果智能体忘记了先前的约束或计划,说明上下文压缩或检索策略存在缺陷。
- 归因至编排层:如果智能体陷入死循环或过早停止,说明生命周期控制逻辑(如重试机制)需要调整。
- 归因至执行层:如果因环境依赖缺失或权限不足导致失败,说明沙箱配置有问题。
- 归因至任务说明:模糊的任务要求可能导致智能体在起步阶段就产生规划歧义。
- …
6. Stage 5 - Continuous Regression and Deployment Feedback
阶段 5 是一轮评估生命周期的终点,也是下一次迭代的起点。这一阶段要回答的核心问题是:评估结果如何驱动 Harness 持续进化?
首先,我们需要构建针对 Harness 的回归评估(regression evaluation)系统。回归评估不仅在模型更新时触发,在 Harness 组件发生任何变动时也必须执行(如修改提示词、更新工具 Schema、调整沙箱镜像或权限规则)。这是因为 Harness 的各层级是高度耦合的,某一层级的改进(如更严格的权限控制)可能会导致另一层级(如工具调用逻辑)出现非预期的故障,因此需要这样的回归测试来看护端到端的性能。而为了应对长程 Agent 的复杂性,作者提倡建立一套分层的评估体系:
- 单元级测试: 验证工具 Schema 的正确性和确定性验证器。
- 单步测试: 针对特定的决策点进行局部验证。
- 全回放测试: 对端到端的任务完成度进行完整测试。
- 多轮模拟: 专门针对长周期任务的一致性进行测试。
LangChain 的 deep-agent evaluation 体现了这种分层的思路。
此外,作者认为任务评估不应孤立存在,而应嵌入到现代化的 LLMOps 流程中,利用现有的通用评估框架,如 DeepEval (看 README.md 有点像 LLM 时代的 UT 框架?)。
最后,论文特别提到了 Meta-Harness 这一前沿方向。它的核心点在于,将 Harness 设计本身作为自动化搜索和优化的对象。与其仅评估模型在固定 Harness 下的表现,不如利用评估信号来寻找能产生最可靠行为的提示词策略、工具接口或控制循环结构。
7. Summary
上述五个阶段共同推动了评估范式的两大转变:
- 从“排行榜机制”转向“质量控制循环”: 评估不再只是为了给模型排个名次,而是为了构建一个针对 Harness 的质量控制环。它通过持续的反馈流,不断修正假设并优化基础设施。
- 从“结果导向”转向“过程归因”: 最终的成功率仍然有用,但不够充分。对于长程 Agent 而言,核心的评估问题不仅仅是任务是否执行成功,而是它为什么成功或失败、路径是否可接受、评估器是否可信,以及下一个应该改进哪个 Harness 组件。
总结来说,这五个阶段构成了一个严密的工程闭环:Stage 1 和 2 确保了测试的准确性,Stage 3 提供了透明度,Stage 4 进行诊断,而 Stage 5 则赋予了系统进化能力。