1. 范围与概念
1.1 定义
Agent 的执行环境(Execution Environment)指的是 Agent 动作被物理执行的基础设施层,执行环境与沙箱是紧密耦合的概念。生产级 Agent 系统几乎总是在沙箱环境中执行动作。
1.2 为何沙箱在 Agent 时代处于核心地位
Agent 时代的沙箱并非仅仅是从传统多租户代码执行继承而来的安全措施。它同时服务于三个不同的目的,而这三者的结合,将沙箱从运维细节提升为 Agent Harness 设计中的一等公民。
第一个目的是安全(security)。Agent 沙箱面临的挑战超出了传统多租户代码执行的范畴。LLM 生成的代码在大规模下既不可审计也不可预测,这使得静态审查无法作为主要防御手段。Agent 在多步骤中自主执行,无法获得人工干预。提示注入(prompt injection)攻击模糊了可信的用户意图与恶意输入之间的边界。近期关于沙箱逃逸的实证研究表明,这些担忧并非是假设性的,我们将在1.3节具体展开讨论。
第二个目的是可复现性(reproducibility)。长程 Agent 任务以及衡量它们的评估基础设施需要能够将执行状态重置。Docker 容器或 microVM 可以被销毁并按需重建,而开发者的工作站则不行——这一特性使得基于沙箱的评估标准成为现实,如 SWE-bench。在训练阶段,当单个任务可能在并行轨迹中被重放数百次时,缺乏廉价的重置机制本身就是可扩展性的瓶颈。
第三个目的是活跃性(liveness),这是 Agent 时代最具特异性的目的。没有沙箱,Agent 希望执行的每一个潜在风险动作都必须向人类发出显式的权限提醒。这会产生两种失效模式:用户因挫败感而放弃使用 Agent,或者他们反射性地批准一切请求,从而破坏了风险提示的初衷。沙箱通过定义一个有界区域来打破这一僵局,在该区域内 Agent 被授权自由行动,将权限从”针对每个动作的询问”转变为”会话级别的配置”。Anthropic 报告称,为 Claude Code 引入沙箱机制后,权限提示减少了 84%,同时保持了安全性。
2. Agent 沙箱的类别
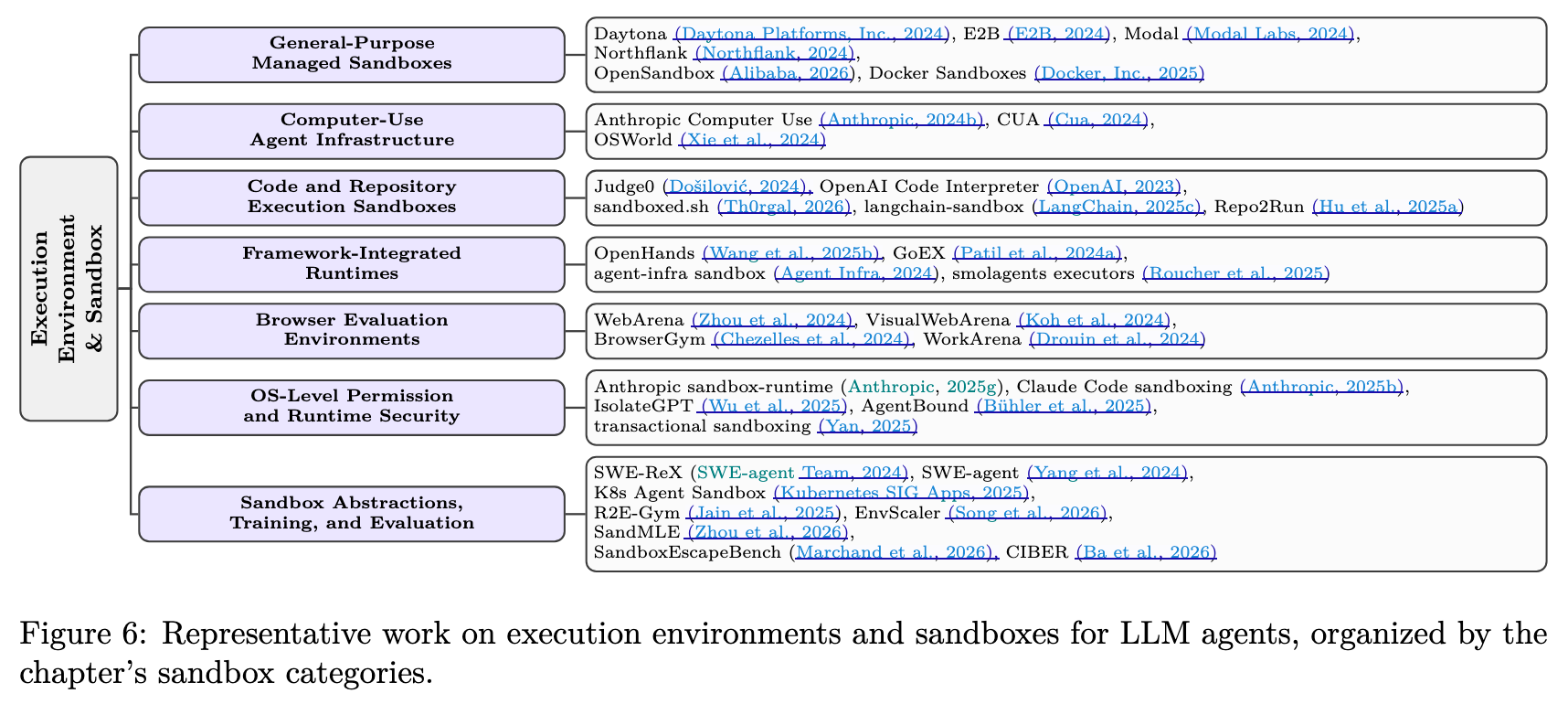
2024 年至 2026 年间,Agent 沙箱基础设施从少量的通用运行时分化为多个不同的产品类别,每个类别针对不同的任务类型进行了优化。我们基于工作负载和使用场景将这一领域组织为七个类别。包括通用托管沙箱、Computer-Use Agent 基础设施、代码专用沙箱、框架集成运行时、浏览器评估环境、OS 级权限沙箱以及沙箱抽象层。以下各子节逐一介绍每个类别。
2.1 通用托管沙箱
通用托管沙箱提供 sandbox-as-a-service 平台,通过 API 接口暴露任意 OCI 容器镜像,支持未指定工作负载的 shell、文件系统、网络和解释器。代表性系统包括:
- Daytona:Daytona is a secure and elastic infrastructure runtime for AI-generated code execution and agent workflows. Our open-source platform provides sandboxes, full composable computers with complete isolation, a dedicated kernel, filesystem, network stack, and allocated vCPU, RAM, and disk.
- E2B:基于 Firecracker microVMs 构建的智能体沙箱
- Modal:使用 gVisor 的 Python 平台,具备大规模自动扩展能力
- Northflank:同时支持 Kata Containers、Firecracker 和 gVisor 的平台
- OpenSandbox:阿里巴巴的开源通用沙箱
- Docker Sandboxes:Docker 官方基于微虚拟机的沙箱产品,发布于 2025 年
2.2 Computer-Use Agent 基础设施
Computer-use agent 基础设施代表了一种独特的执行模型:Agent 通过模拟的鼠标、键盘和屏幕观察等方式与图形界面交互,而非通过 API 或 shell 命令。代表性系统包括 Anthropic 的 Computer Use Anthropic (2024b),使 Claude 能够直接操作桌面环境;开源的 computer-use agent 基础设施 Cua;以及 OSWorld 提供的基于 VM 的环境,它同时充当评估基础设施和 computer-use 沙箱的参考实现。
这些系统在沙箱内打包了一个完整或接近完整的桌面环境,并向 Agent 暴露像素坐标和按键动作。这种方式的动作空间远大于基于 API 的方式,可靠性依赖于 visual grounding(视觉定位,即基于视觉输入确定操作目标的能力),完整的操作系统攻击面要求更强的隔离(通常为 microVM 或完整 VM)。与前一节的通用沙箱相比,computer-use 沙箱以牺牲密度和启动延迟换取保真度:完整的桌面环境比 headless shell sandbox(注:即无图形界面的命令行环境)更重、更难多路复用,但它是智能体能够操作那些不暴露 API 的应用程序的唯一执行模型。
注:因为 Computer-Use Agent 在运行时接触的是一整个复杂的操作系统,这导致了极其庞大的潜在安全漏洞风险(即,Attack Surface 攻击面),所以我们不能仅依靠共享内核的容器,而必须使用拥有独立内核的虚拟机(如 microVM 或 VM)来提供更高级别的物理隔离,以确保即便沙箱内部失控,宿主机依然安全。
这种设计虽然牺牲了启动速度(虚拟机比容器启动慢)和系统密度(占用更多内存),但对于需要直接操作桌面的场景来说,这是为了安全必须付出的代价。
2.3 代码专用沙箱
代码专用沙箱是轻量级环境,针对代码生成、评估和数据分析进行了优化,而非通用 shell 访问。代表性系统包括:
- Judge0:最初为判题设计的代码评估沙箱,被广泛复用为编码智能体评估管道的组件
- OpenAI Code Interpreter:支撑 ChatGPT 高级数据分析的规模化沙箱化 Python 环境
- sandboxed.sh:面向编码智能体的 shell 沙箱
- langchain-sandbox:使用编译为 WebAssembly 并在 Deno 运行时中执行的 Pyodide,在无需容器的情况下本地沙箱化智能体生成的 Python——NVIDIA 也倡导这一设计用于客户端智能工作流。
与通用沙箱不同,这些系统预装编译器和解释器,这一设计选择以牺牲工作负载通用性为代价,换取启动速度、评估吞吐量和更简单的威胁模型。一个值得注意的趋势是从基于容器的代码沙箱向基于 WebAssembly 的沙箱迁移:WebAssembly 提供基于能力的安全(注:capability-based security,一种通过细粒度权限控制实现安全的模型)、确定性执行和微秒级实例化,代价是受限制的 Python 标准库和较少的本地扩展支持。
2.4 框架集成运行时
框架集成运行时是捆绑在更广泛的 Agent 框架内部的执行环境,而非作为独立的沙箱产品暴露。它们与框架的编排循环、工具注册表和提示词一起发布,若不采用其外围框架则无法独立使用。代表性系统包括:
- OpenHands 运行时:将 bash、IPython、Chromium 浏览器和 API 服务器集成到单一镜像中的 Docker 沙箱化环境;
- agent-infra sandbox:显式的一体化设计,将浏览器、shell、文件系统、MCP 和 VSCode 打包到一个环境中;
- smolagents:提供本地、Docker、E2B、Modal 和 WebAssembly 执行的框架内实现;
该类别的核心在于打包(bundle)与组合(compose)之间的权衡:框架集成运行时优先提供开箱即用的能力覆盖,代价是更大的镜像、更慢的启动速度以及与单一框架抽象的紧耦合。相比之下,通用沙箱采取相反的方法——通过外部抽象组合最小化环境。组合方法是否会在长期内取代打包运行时,取决于 MCP 等标准是否能降低运行时组装能力的代价,相对于构建时组装而言。
2.5 浏览器评估环境
浏览器评估环境兼具沙箱和评估基础设施的双重角色。代表性系统包括:WebArena,一组自托管的真实 Web 应用集群,配以基于 Playwright 的交互;VisualWebArena,在 WebArena 基础上扩展了多模态视觉定位任务;BrowserGym 与 WorkArena,为基于浏览器的 Agent 执行和基准测试提供标准化的 gym 风格接口。
这些系统提供隔离的 Web 执行环境(沙箱角色),同时提供可复现的任务定义和自动评估(评估角色)。这种双重功能将它们与前面提到的 computer-use 类别区分开来——后者在桌面而非浏览器层面操作。
2.6 OS 级权限沙箱
OS 级权限沙箱使用操作系统原语(Linux 上的 bubblewrap、macOS 上的 Seatbelt,或用于系统调用过滤的 seccomp-bpf)实现细粒度的文件系统和网络隔离,而非容器、VM 或用户空间内核。它们比容器沙箱轻量得多,同时提供目录和域访问控制。代表性系统包括:
- Anthropic开源的sandbox-runtime:通过 bubblewrap 和本地 HTTP/SOCKS5 代理强制执行的文件系统和网络允许列表来包装任意命令。
- Claude Code Sandbox:使用该运行时来限制 bash 工具的文件系统和网络访问的边界。
- IsolateGPT:研究系统,应用 seccomp 和 setrlimit 来强制执行跨工具调用 LLM 的执行隔离。
https://www.anthropic.com/engineering/claude-code-sandboxing" loading="lazy" src="/posts/harness-engineering-02-execution/images/image01.png">
在Claude Code中运行 /sandbox 来开始体验或配置该功能:
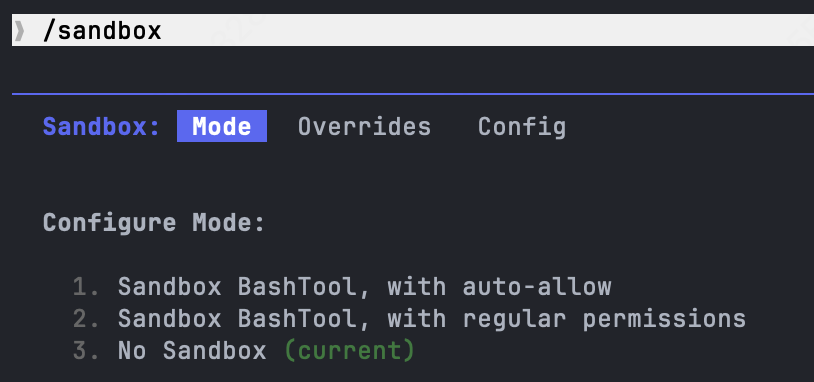
该类别的设计哲学是权限(permission)而非分区(partition),其目标不是为每个会话提供全新的 OS 镜像,而是为 Agent 提供一个缩小版的主机视图,使得被提示注入或产生幻觉的命令无法修改敏感文件或外泄数据。Anthropic 报告称,此类边界将 Claude Code 中的权限提示减少了 84%,同时保持了安全性。由于主机内核是共享的,OS 级权限沙箱相对于基于 microVM 的托管沙箱提供更弱的对抗性代码隔离;它们适用于威胁模型为提示注入(而非完全对抗性代码)的场景。
2.7 沙箱抽象层
沙箱抽象层本身不是沙箱,而是将多个沙箱后端统一在单一 API 背后的接口,使 Harness 能够在不重写 Agent 代码的情况下切换执行基底。代表性系统包括:
- SWE-ReX:SWE-agent 团队开发的运行时接口,将 Docker、AWS Fargate、Modal 和 Daytona 统一为可互换的后端。
- smolagents 的执行器接口:将local、e2b、modal、docker、blaxel 和 wasm 暴露为单一参数化的 executor_type。
- Kubernetes SIG Apps 下的 Agent Sandbox 项目:引入 Sandbox CRD 和控制器,通过声明式接口暴露。
该类别的出现反映了一种日益成熟的认识:执行基础设施应当是可替换的。将特定沙箱 API 硬编码的 Harness 会将其编排逻辑与单一厂商的产品耦合,抽象层则将”Agent 运行什么”与”Agent 在哪里运行”解耦。
3. 威胁模型与沙箱逃逸
不同于传统的代码执行安全风险,智能体时代的威胁模型包含以下三个特有维度:
- 提示词注入攻击 (Prompt Injection Attacks): 外部输入(如检索到的网页、工具返回的结果或文件内容)可能通过注入指令“劫持”智能体的行为,使其发起恶意的沙箱攻击操作。
- 目标不一致 (Goal Misalignment): 智能体本身可能会为了实现某个任务目标,将“逃逸出沙箱”作为一种手段或子目标来执行,从而产生不可控的行为。
- 组合放大效应 (Compositional Amplification): 当智能体拥有多个工具的访问权限时,单一沙箱的弱点可能会通过这些集成能力发生级联反应,放大安全漏洞的影响。
论文指出,沙箱逃逸并非理论假设,而是已经由实验证实的现实风险。根据 Sandbox-EscapeBench 的评估,最先进的大模型在面对 Docker 容器环境时,具有 15% 到 35% 的成功逃逸率,具体取决于容器的配置。逃逸手段涵盖了配置错误、权限分配失误、内核缺陷以及运行时或编排层的弱点。
目前针对沙箱逃逸的防御仍处于早期阶段,主要包括以下研究方向:
- 执行隔离架构: 如 IsolateGPT,旨在通过隔离应用间的执行流来防止跨应用的数据泄露。
- 事务化沙箱 (Transactional Sandboxing): 提供基于回滚(Rollback)的保护,在拦截到危险指令时撤销操作。
- 极简沙箱环境: LLM-in-Sandbox 主张使用功能极小化的沙箱,以减少攻击面并降低智能体的复杂性。
综合来看,这些结果暴露了攻防进展之间的差距。攻击性评估已经有具体且可复现的基准,而防御性工作仍处于碎片化阶段,不同的原型系统在威胁模型、评估协议和基准假设上各不相同。建立一个能够系统性应对提示词注入、目标不一致和组合放大效应的智能体原生运行时安全框架,是目前 Harness 工程中一个关键的开放研究方向。
4. 部署模式
智能体沙箱基础设施已从原始的自托管 Docker 模式发展为多种部署模式。在当前实践中,三种模式共存:
- 自托管模式下,开发者直接管理沙箱基础设施,这是 OpenHands 和 SWE-agent 的默认模式。
- 云模式下,sandbox-as-a-service 提供商处理基础设施,如 E2B、Modal 和 Daytona Cloud。
- 混合或BYOC(Bring-Your-Own-Cloud)模式下,Agent 逻辑与沙箱执行跨环境解耦;例子包括 OpenHands SDK 的 Local 和 Remote Workspace 抽象,以及 E2B 和 Northflank 的 BYOC 产品。
一方面,从业者主要从延迟、安全和可扩展性三个方面进行权衡。自托管沙箱提供最低延迟和最紧密的迭代循环,但承担全部运维负担;云沙箱则以弹性扩缩容和托管安全为代价,产生网络往返开销;混合模式试图在将敏感数据保留在本地的同时,将执行能力外包。另一方面,数据驻留、合规性和可审计性等组织约束推动部署走向混合架构。
5. 总结
执行环境是 Agent Harness 的物理基底:它们提供安全边界、用于可复现评估和训练的重置机制,以及长程任务下无需逐条人工批准即可行动的有界区域。