Harness Engineering 系列文章以 Agent Harness Engineering: A Survey 为基础进行整理。
Agent = Model + Harness
学术界对 LLM-based Agent 的研究,很大程度上一直是对模型本身的研究。研究主要聚焦于模型能做什么:它是否能跨多步规划、可靠的调用工具、检索并压缩相关记忆,或与其他智能体协调等。其隐含假设是,智能体能力主要取决于模型能力——只要有足够强大的模型和足够好的提示词,就能产生足够可靠的输出。
然而,最新的研究挑战了”仅靠更好的模型就能产生更可靠的智能体”这一假设。三项最新的研究确定了这一点:
- Bölük (2026) 仅修改了编辑工具的格式和工具 harness,未对模型做任何改动,就在15个模型上实现了编码基准测试高达10倍的提升。
- LangChain (2026) 仅通过系统提示词重构、中间件上下文注入和自验证钩子,就将 GPT-5.2-Codex 智能体在 Terminal-Bench 2.0 上的表现从 52.8% 提升至 66.5%——13.7个百分点的提升完全来自基础设施层面的改动。
- Meta-Harness (2026) 通过 automated harness 优化,在 Terminal-Bench-2 上达到 76.4%,超越了所有手工设计的方法,且未修改任何模型权重。
以上每种情况,变量都是 harness(即控制上下文构建、工具交互、编排、反馈和执行约束的基础设施层),而模型保持不变。仅靠 harness 优化,就足以实现大幅性能提升,这种模式并非偶然:harness,而非模型本身,是驱动可靠性的关键因素。
论文将这一模式称为“binding-constraint thesis(约束绑定论)”,即对于长程任务的评估,基准测试的方差可能由 harness 和模型共同驱动。本文以此论题作为后续论述的框架。
Agent 系统的演进
ReAct 时代(2022–2023)。ReAct 将 observe-think-act loop 确立为一种基础原语。早期系统的基础设施极为精简:一个 while 循环、一个提示模板和一个小型的工具分发表。AutoGPT 和 BabyAGI 展示了通过任务队列、记忆和工具调度来包装语言模型调用以实现完全自主运行的雄心,同时也暴露出执行失控、上下文膨胀、状态丢失等问题。这些并非单纯的提示问题,而是基础设施问题。
工具集成与多智能体协调(2023–2024)。Gorilla、ToolLLM 和 Toolformer 的研究表明,工具使用能力可以通过学习或引导产生;CAMEL、ChatDev、MetaGPT 和 Mixture-of-Agents 引入了多智能体协调模式,涵盖角色扮演对话、软件开发组织架构以及分层智能体聚合等多种形式;随着 SWE-bench、AgentBench、WebArena 和 GAIA 的推出,evaluation infrastructure(评估基础设施)日趋成熟;协议标准化则以 Anthropic 的 MCP 和 Google 的 A2A 为起点。
Harness(2025–2026)。到 2025~2026 年,工业界逐渐把注意力转移到 Harness 上。OpenAI 明确将 “harness engineering” 定义为围绕 Codex 智能体设计环境、约束、文档和反馈循环的学科,并于2026年2月报告称,一个小团队在5个月内通过智能体而非手工编写生产代码,产出了约一百万行内部产品代码;Anthropic 的博客也得出了同样的原则:有效的智能体应使用简单且可检查的架构(Building effective agents);工具接口应为智能体使用而设计,而非照搬面向人类的 API(Writing effective tools for agents — with agents);上下文应渐进式披露(Effective context engineering for AI agents);长程工作需要持久化的交接工件和可恢复的执行基础设施(Effective harnesses for long-running agents, Harness design for long-running application development);软件工程领域的权威人物 Martin Fowler(注:即《重构-改善既有代码的设计》作者) 在其博客 Harness engineering for coding agent users 中将 harness engineering 描述为 “AI 智能体的控制论调节器”,由围绕 LLM 形成控制回路的前馈引导和反馈传感器组成。
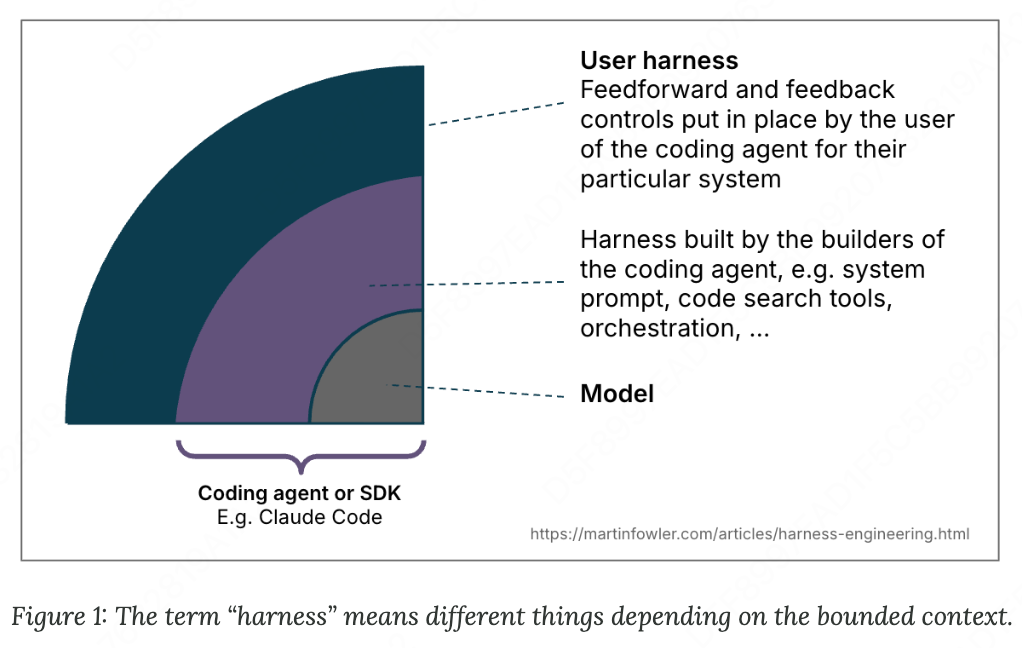 引用 https://martinfowler.com/articles/harness-engineering.html
引用 https://martinfowler.com/articles/harness-engineering.html
在此期间,该领域在”选择工程化什么”这一问题上呈现出清晰的三个阶段。
第一阶段是提示工程(Prompt Engineering, 2022–2024)。核心手段是输入提示文本,通过精心设计的指令、少样本示例和推理模板来进行优化。工程范围较为局限:优化单个文本输入以完成单次模型调用。
第二阶段是上下文工程(Context Engineering, 2025)。随着 Agent 的运行周期变长,核心约束从 “输入是什么” 转变为 “模型在每一步应该看到什么信息”。这一阶段聚焦于上下文管理:每一轮注入什么内容、如何检索和压缩记忆、如何按相关性对工具结果排序,以及如何处理上下文窗口饱和。范围从管理单个输入扩展到管理流入上下文窗口的多条信息流。
第三阶段是Harness 工程(Harness Engineering, 2026)。随着模型能力足以处理长程任务,可靠性越来越依赖于维护状态、协调工具、注入反馈、强制执行约束和验证进度的基础设施包装层。因此,Harness Engineering 关注的是:必须围绕模型设计什么样的治理、约束、反馈循环和执行控制,才能使智能体系统可靠。
每个阶段都包含前一个阶段,Harness Engineering 包含 Context Engineering,Context Engineering 包含 Prompt Engineering。三个阶段在时间上和概念上相互重叠,并没有明确的边界。
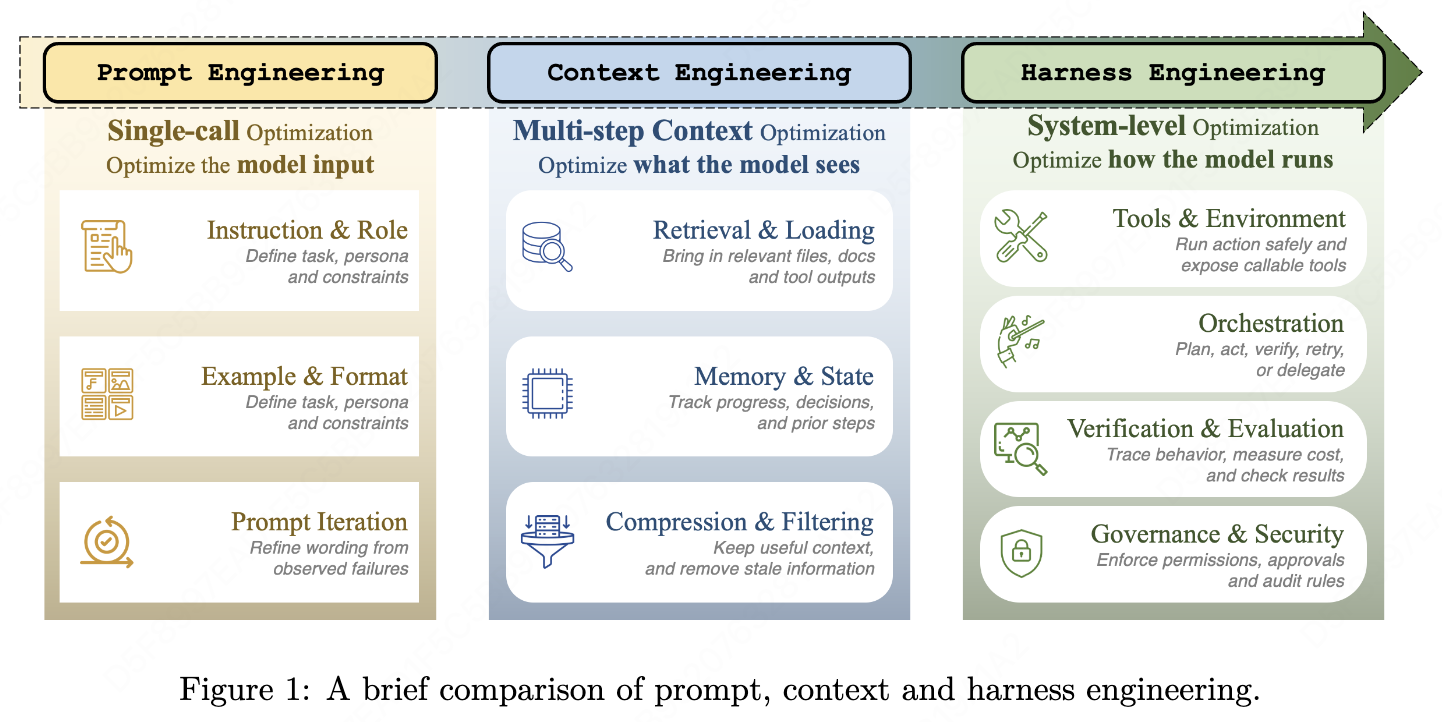
Harness 究竟是什么
论文提出了 Harness Engineering 七层分类体系,称为ETCLOVG,分别代表 Execution(执行)、Tooling(工具)、Context(上下文)、Lifecycle(生命周期)、Observability(可观测性)、Verification(验证)和 Governance(治理),如下所示。
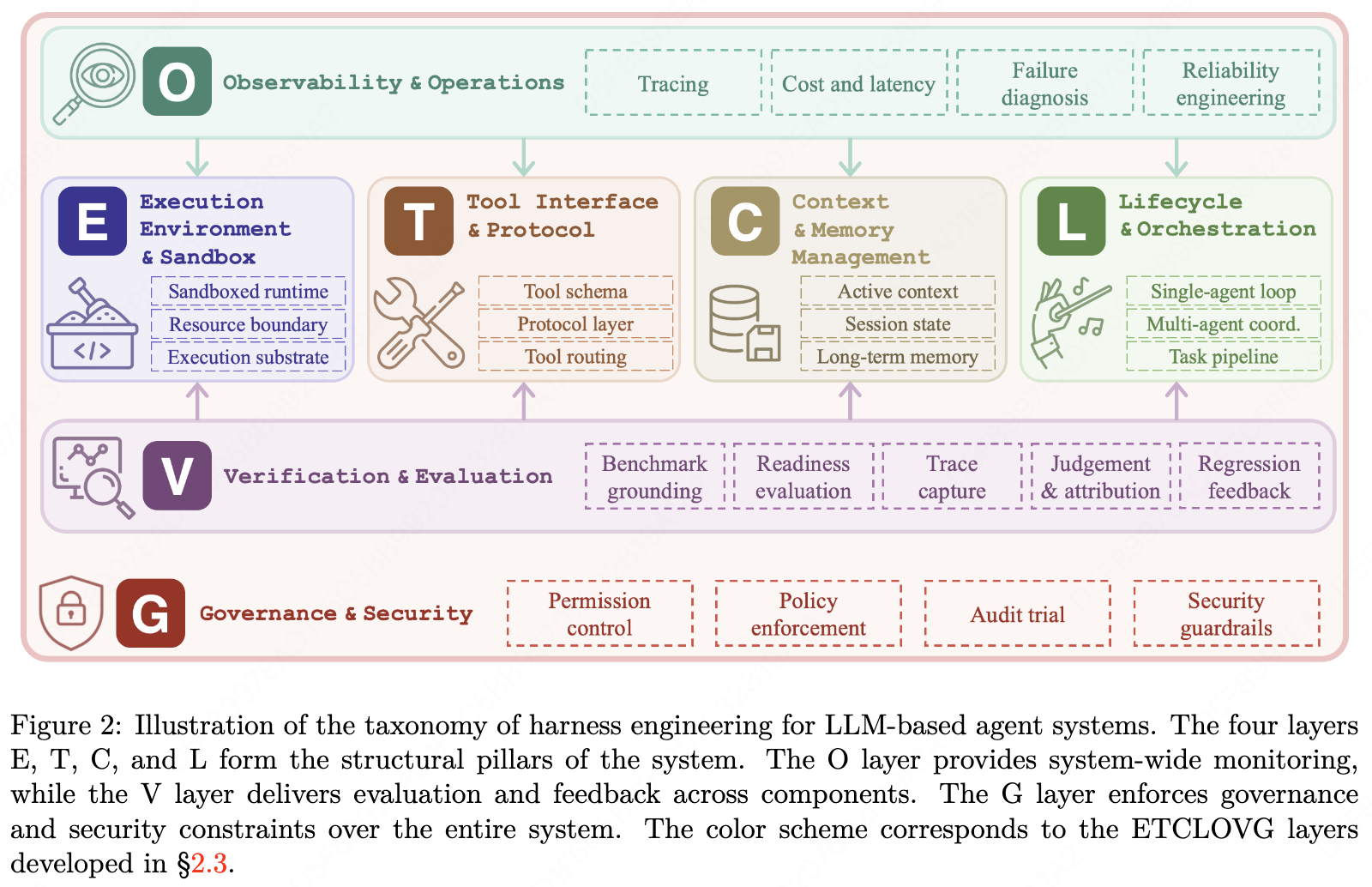
前四层描述了 Harness 的核心结构,后三层则是围绕该核心的控制平面。
- Execution:执行环境。Agent 在哪里跑?本地、容器、浏览器、桌面、远程沙箱?边界在哪里?
- Tooling:工具接口。工具怎么描述,怎么发现,怎么调用,怎么防止模型乱选工具?
- Context:上下文和记忆。短期上下文、会话状态、长期记忆怎么管理?
- Lifecycle:生命周期和编排。一个 Agent 是单轮执行,还是多轮循环?是一个 Agent 干到底,还是 planner、executor、reviewer 分工?
- Observability:可观测性。每次模型调用、工具调用、检索、报错、重试、token 成本、延迟,都要能追踪。
- Verification:验证和评估。结果对不对?失败到底是模型错了、工具错了、上下文错了,还是测试环境错了?
- Governance:治理和安全。Agent 有什么权限?能不能发邮件、改代码、调 API、读私有数据?谁来审批?谁来审计?
很多人理解 Agent,可能还停在“模型 + 工具调用 + 上下文管理” 这一层。这篇论文给出了更加系统化的定义,真正的 Agent 产品,在模型之外,还需要以上 7 层组件的共同协作。否则,它可能只是个能够演示的 demo,不足以支撑长期稳定的运行。