在日常的 Agent 开发中,开发者很难直接接触到服务端的 KV Cache。然而,无论是编写 Prompt、控制对话历史的长度,还是设计 Agent 的长程反思循环,其本质都在操纵 KV Cache 的计算与复用。本文旨在系统化拆解 KV Cache 与 Prompt Cache 的工作机制,分析其在多轮对话与 Agent 架构中的应用设计原则,并深入探讨在百万级用户规模下,分布式推理系统在安全性、多级存储管理、以及调度计费上面临的工程权衡。
1. 核心概念:Prompt Cache 与 KV Cache
1.1 Prompt Cache 与 KV Cache 的区别
要理解大模型推理的成本与时延,首先必须厘清两层性质完全不同的“缓存”概念。它们处于不同的生命周期,服务于不同的系统目的:
| 维度 | 运行时 KV Cache | 前缀复用缓存 (Prompt Cache / Prefix Cache) |
|---|---|---|
| 主体对象 | 某个正在进行的单次生成请求,独占该内存块 | 已结束请求留下的、可供后续跨请求复用的前缀 KV 块 |
| 存活周期 | 即时焚毁:随请求开始而创建,随生成结束(吐出 EOS)而彻底释放 | 持久留存:请求结束后不丢弃,在内存/硬盘中留存一段时间(TTL) |
| 系统目的 | 维持 Self-Attention 机制的多轮解码,让当前的 Token 生成得以持续 | 跳过后续相同前缀请求的 Prefill 阶段,直接加载计算结果 |
| 核心效益 | 将自注意力计算复杂度从 O(N^2) 降低到 O(1) | 极端优化首字延迟(TTFT)与算力成本 |
1.2 Prompt Cache 缓存了什么
在 Prefill 阶段,推理引擎将 Prompt 中的每个 Token 转换为 K, V 向量填入缓存。Prompt Cache 做的事情,是在当前请求结束后,将这段已经算好的 KV Cache 留在服务端。下次请求若 Prompt 前缀相同,则直接加载这块 KV,跳过对这段前缀的 prefill。
|
|
关键推论:Prompt Cache 不省 Decode 的算力,输出 Token 依旧需要逐字生成并全价计费。它优化的是 Prefill 阶段,若命中相同前缀的 Prompt,可以直接加载对应的 K, V 矩阵,直接优化 TTFT(首字响应时间),对“长输入、短输出、高频复用”的场景收益最大。
2. 为什么命中规则是前缀匹配
在工程实践中,Prompt Cache 的命中规则被严格限制为“连续前缀匹配”。这是由注意力机制的因果性(Causality)决定的物理必然。
在 Decoder-Only 架构中,每个 Token 的 K, V 向量不仅由其自身决定,还唯一依赖于其左侧所有的 Token 序列。一旦前面的任何一个 Token 发生改变,从该位置往后的所有自注意力都会发生扰动,导致后续的 K, V 矩阵全部作废。
|
|
基于前缀匹配的物理特性,Prompt 的排列组合必须遵循“稳定前置,动态后置”的架构原则。
✅ 正确范式(最大化缓存命中)
|
|
❌ 错误范式(导致缓存全盘击穿)
|
|
3. 由 Prompt Cache 引出的 Agent 设计原则
多轮对话与 Agent 的 ReAct 循环,是 Prompt Cache 的最佳天然搭档。因为从本质上看,对话历史与工具状态的演进,表现为“只增不改的前缀账本”。
在一个标准的 Agent 任务中,上下文随着步骤呈滚雪球式增长:
|
|
在没有 Prefix Cache 的传统推理中,每次请求都需要对越来越长的历史进行重复的 Prefill 计算(造成二次方级的算力浪费);而开启缓存后,每次迭代仅需对新增的 [Tool Result] 进行增量 Prefill,Agent 的任务步数越多,缓存带来的成本与时延优势越大。
为了在复杂的 Agent 开发中守住缓存命中率,开发者必须遵守以下三条硬性原则:
- 工具定义(Tools Schema)静态化:将包含海量 JSON schema 的工具描述置于最前,应尽量避免在运行中动态增删工具,防止全盘击穿。
- 工具返回结果的“字面确定性”:确保相同输入的工具返回内容在文本层面完全一致。若返回的 JSON 内部带有随机排序(比如,map的返回结果不保证严格有序)或非必要的辅助性元数据(比如
queried_at细粒度时间戳),虽然单次会话内已固化的历史不受影响,但会破坏跨请求/跨任务之间的缓存复用。 - 警惕“中间插入/改写历史”:任何中间插入都会令插入点之后的所有 KV 缓存作废。因此,严禁在历史上下文的中间(如多轮对话中央)动态插入 RAG 的召回片段。再比如,为了省 Token ,会在上下文变长后把前面几轮内容做摘要并替换掉原文,这会导致后面全部缓存失效。压缩历史能省 Token,但会牺牲缓存命中,因此要权衡。
4. 工业级大规模推理服务的工程权衡
当视角切换到服务上亿用户的云端推理平台(如 OpenAI、DeepSeek、vLLM 自建集群)时,管理海量并发下的 KV Cache 演变为一场关于安全性、内存容量以及硬件调度的极限游戏。
在推理服务端,是如何做缓存的呢?尤其是针对不同用户的请求,彼此之间不会混淆搞串了吗?假设用户A命中了用户B的cache,那不就涉及到了信息泄露等问题?用户量如此之大,推理服务端又是如何存下所有用户的缓存呢?等等。即,KV Cache/Prompt Cache 在真实的工程视角下,涉及数据安全、容量、调度、计费等一整套工程权衡。
4.1 安全屏障
1、内容寻址(Content-Addressing)的安全性
在服务端,系统通过对前缀 Token 序列进行哈希计算来生成唯一键(Cache Key):
$$ \text{Cache Key} = \text{Hash}(\text{prefix\_tokens}) $$从数学上看,用户 A 想要命中用户 B 的缓存,其前缀必须与 B 逐字完全等价。既然内容完全一致,其对应的 KV 矩阵即为确定性计算结果,因此复用缓存并不存在“读取到他人私密数据”的直接数据泄露风险。
2、隐蔽的时序侧信道风险 (Timing Side-Channel)
尽管内容无法被直接窥探,但由于“命中缓存的首字时延远快于未命中”,攻击者可以通过高精度时间探测,推断出其他用户是否输入过相同的敏感内容:
|
|
3、工业级防御方案
为了彻底绝绝此类侧信道探测,主流云厂商采用了按组织/租户强隔离的命名空间机制:
$$ \text{Cache Key} = \text{Hash}( \text{org\_id}+\text{prefix\_tokens}) $$通过引入 Org_ID,纵使不同组织的用户输入了完全相同的系统提示词或敏感文本,其哈希键也绝不交叠。虽然这牺牲了部分公共前缀的全局复用率,但保障了企业级数据的绝对安全。
4.2 容量决策
1、分层缓存架构
大模型(如 70B 及以上参数模型)的 KV Cache 体积巨大。在有限的硬件预算下,无节制地留存所有前缀是不可能的。工业界普遍采用分层缓存架构。
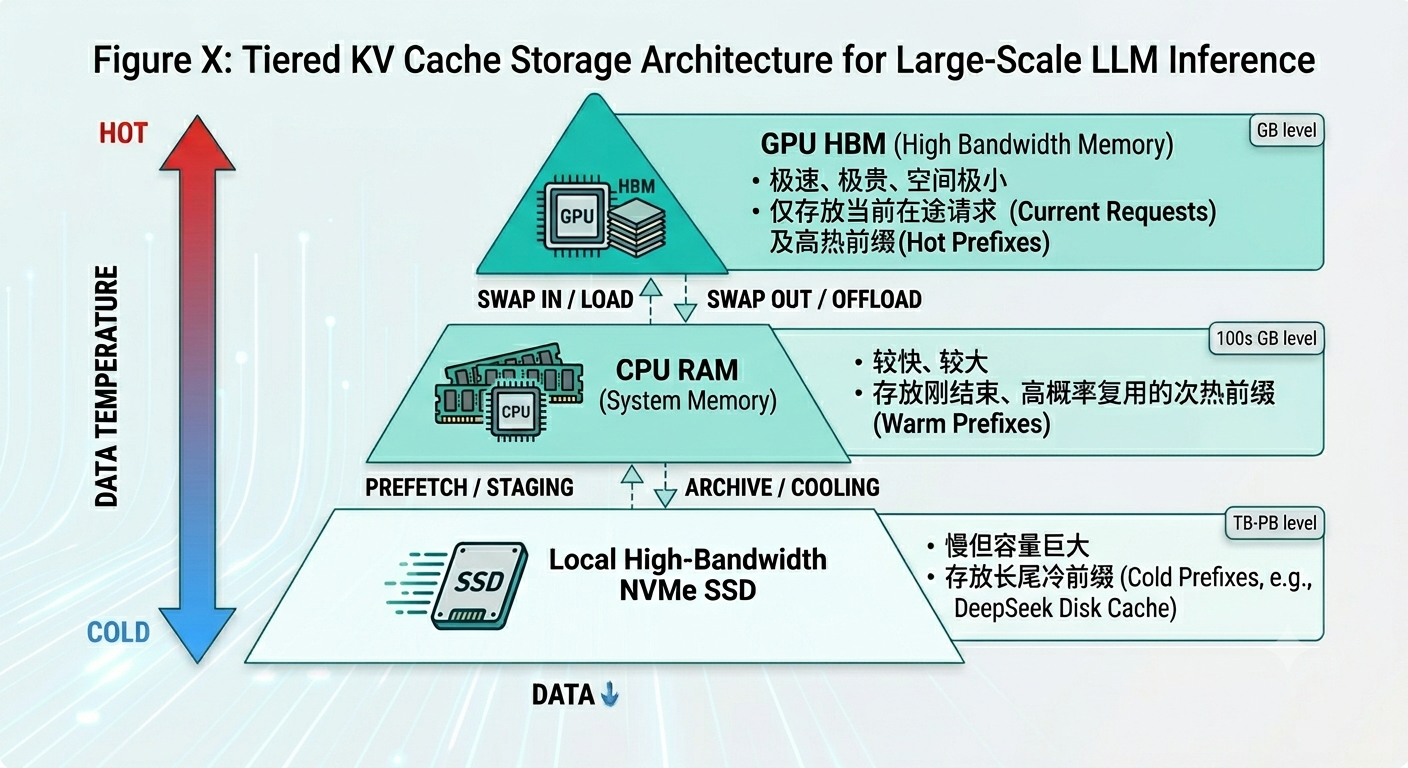
DeepSeek 引入磁盘级 Context Cache 方案,不仅大幅降低存储成本,在性能方面,即使存在 SSD I/O 延迟,128K 请求的 TTFT 仍从 13s 降至 500ms,远快于重新 Prefill。
2、驱逐策略与动态淘汰
当各级存储空间触及水位线时,系统启动自动淘汰:
- LRU(最近最少使用):优先剔除最久未被命中的前缀。
- TTL(生存时间生存期)机制:为缓存强制设定过期窗口(例如 Anthropic 默认的 5 分钟)。到期即焚,在释放空间的同时,也大幅收窄了侧信道攻击的暴露窗口。
4.3 调度优化
为了让海量请求在同一个 GPU 节点上高效并行,现代推理引擎(如 vLLM)在底层实现了虚拟内存管理。
- PagedAttention 消除碎片:传统显存分配会为请求预留连续的、最大可能长度的空间,造成高达 60%-80% 的内存碎片。PagedAttention 将 KV Cache 切碎为固定大小的“物理块(Blocks)”,允许非连续存放,通过块表映射逻辑顺序,实现物理块的“写时复制(Copy-on-Write)”,这也是 Prefix Cache 实现多请求安全共享同一段内存的底层基石。
- 连续批处理(Continuous Batching):在解码阶段,将数十个不同用户的请求动态打包进同一个计算 Batch。批处理打包的是计算指令,而各请求的 KV Cache 在内存物理块上依然强隔离。
- Prefill/Decode 分离:两阶段资源特征冲突(compute-bound vs. memory-bound),大厂常用不同 GPU 池分别处理,各自优化,互不干扰彼此的延迟。
- Chunked Prefill:超长 prompt 的 prefill 切块,和别人的 decode 穿插执行,避免一个长请求把其他用户的吐字卡住。
5. 再看大模型 API 计费结构
看懂了服务端的 KV Cache 分层与调度,便能完全看透各大主流大模型 API 账单的定价逻辑:
- Cache Write:按标准输入计费,或因需要执行额外的存储持久化操作,部分平台会收取微小的存储溢价。
- Cache Read / Cache Hit:由于免去了昂贵的 Prefill 阶段硬件算力,平台得以让利开发者。
- Output Token:维持全价。因为不管前缀如何复用,自回归解码阶段必须踏踏实实地逐字计算、搬运模型权重,没有任何捷径可走。
以下是 DeepSeek API 定价,数据源自 https://api-docs.deepseek.com/quick_start/pricing
