这一层控制模型在执行的每一步看到什么信息,以及知识如何在多轮对话和会话之间持久化。核心工程问题可以简单表述为:在每一步给模型提供恰好正确的信息,不多不少。上下文太少,Agent 缺乏正确推理所需的状态;太多,则会导致性能下降。

1. 为什么上下文必须被工程化
更大的上下文窗口并不能解决记忆问题。理解这一点,需要从架构层面来分析。
注意力成本。Transformer 的自注意力机制计算上下文中每个 token 之间的成对关系。对于 n 个 token,会产生 n² 个成对权重;计算量和记忆量随上下文长度以 n² 增长。虽然 FlashAttention 和位置编码插值(position-encoding interpolation)等技术可以降低常数因子,但二次方结构是架构性的。这使得上下文窗口成为一种稀缺资源。
U 形注意力曲线。仅靠架构成本并不能解释为什么模型即使在计算可负担的情况下,仍会在长上下文任务上失败。Lost in the Middle 提供了关键的实证结果:在包含 20 个输入文档的多文档问答任务上,当相关文档位于上下文的中间时,准确率比放在开头或结尾时下降超过 30%。这种 U 形性能曲线在不同模型、任务和上下文长度上均成立,包括专门为长上下文训练的模型。这表明信息的摆放位置和信息的客观存在同样重要。一个检索到了正确内容但放置位置不佳的智能体,效果仍然可能比较差。
上下文腐化。上下文腐化(Context Rot)是指随着输入信息的增长,大模型在检索、定位和对上下文信息进行推理的能力会出现非线性的下降。 这并非由于窗口被填满导致的物理截断,而是一种即使在窗口容量充足时也会发生的“性能退化”。根据对 18 种前沿模型(包括 GPT-4.1、Claude Opus 4、Gemini 2.5 等)的对照评估,上下文腐化呈现出以下特征:
- 早发性(Early Onset):性能退化在上下文窗口远未填满之前就开始了。例如,一个支持 200K Token 的模型,可能在输入达到 50K 时就已经表现出显著的性能损失。
- 非均匀性与任务特定性(Task-specific):腐化的程度取决于查询的类型。
- 语义模糊挑战:当查询与目标信息在词汇上不完全匹配时(语义模糊),性能下降比“精确匹配”查询更剧烈。这表明模型在海量信息中识别“隐含关联”的能力最先发生腐化。注:这里描述的是,信息在进入上下文窗口后,模型在思考过程中如何从Prompt里的成千上万个词中提取和关联信息。
- 复合型失败(Compound Failure):腐化是由两个连续的逻辑失效组成的:
- 定位失效(Localization):模型无法从海量 Token 中精准找到相关的片段。
- 推理失效(Reasoning):即便定位到了信息,模型也无法在被大量噪音包围的状态下,对该信息进行正确逻辑处理。
上下文腐化现象并非偶然,对于任何在多个步骤中累积工具结果、中间推理状态和文件内容的智能体来说,这是正常的运行状态。
2. 从 Prompt Engineering 到 Context Engineering
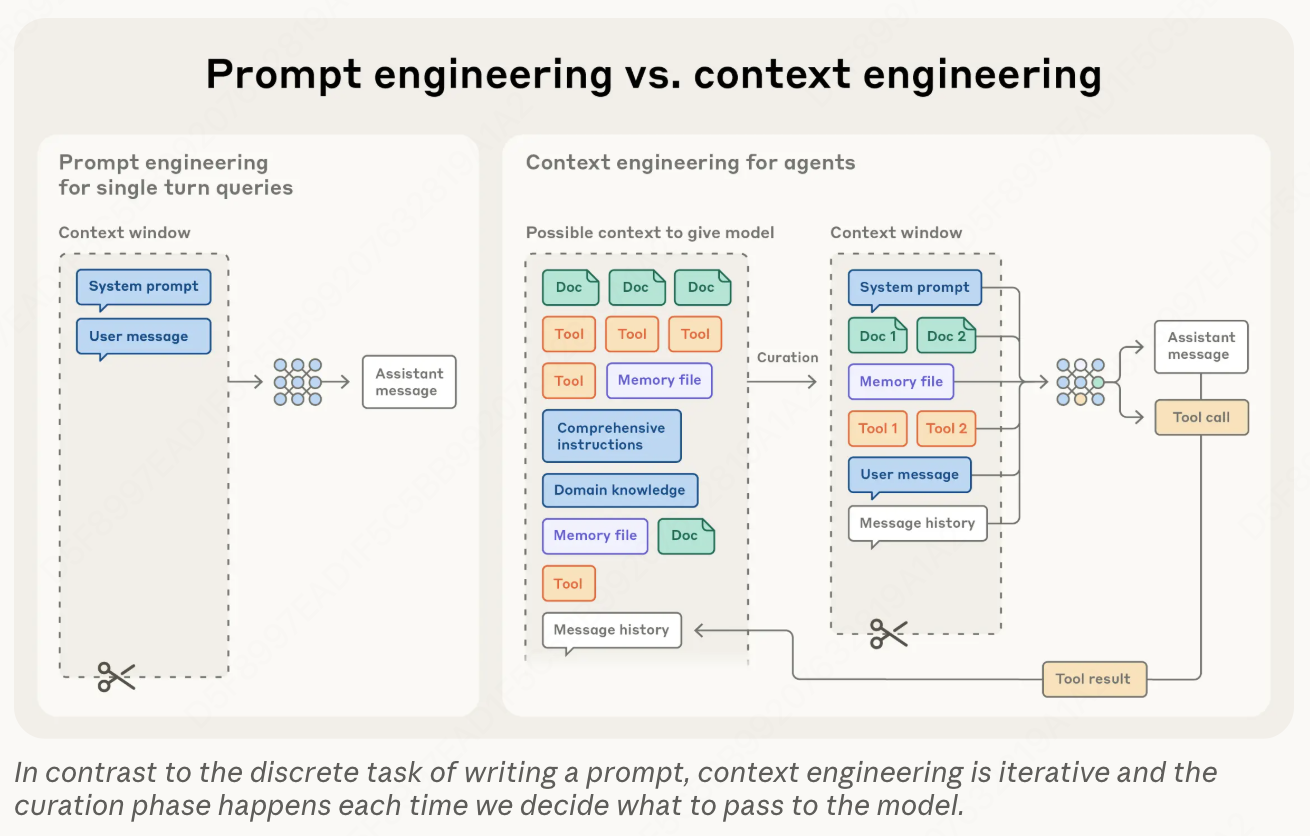
Prompt Engineering 优化的是面向单次模型调用的静态文本输入,Context Engineering 优化的则是多步任务中每一步推理时模型可用的完整信息状态。Anthropic 团队在 Effective context engineering for AI agents 中将 Context engineering 定义为:
Context engineering refers to the set of strategies for curating and maintaining the optimal set of tokens (information) during LLM inference, including all the other information that may land there outside of the prompts.
如何理解这句话?从以下三个维度拆解:
1. “策划与维护(Curating and Maintaining)”:从被动堆叠到主动管理。传统的提示词工程主要关注“输入什么”,通常是单次调用的静态文本优化。而上下文工程认为上下文窗口是一个稀缺资源,必须像操作系统的内存一样进行主动管理。
- 策划(Curating):意味着必须有选择性。由于“U型注意力曲线”的存在,模型往往会忽视上下文中间的信息,因此开发者必须精心挑选哪些信息该进入窗口,放在什么位置。
- 维护(Maintaining):这是一个动态过程。随着任务进行(可能长达上百步),上下文会发生“腐败”,性能随之下降。维护意味着要不断地进行压缩、过滤或清理工具结果,以保持信息的纯净度。
2. “最优 Token 集合(Optimal Set of Tokens)”:追求最高信号密度。这句话的核心逻辑是:在有限的注意力预算内,通过最少的 Token 实现最高的执行成功率。
- 信号密度:不是信息越多越好。过多的 Token 会产生冗余,增加推理成本,并导致模型产生规划错误。
- 准时加载(Just-in-time):采用渐进式披露策略,仅在需要时加载特定文件或数据,而不是一开始就塞满所有背景信息。
3. “提示词之外的其他信息(Information outside of the prompts)”:扩展工程边界。这句话指出了上下文工程的复杂性:它处理的不仅仅是开发者写的指令(Prompts),还包括智能体在运行过程中实时生成的各种动态负载,比如:
- 工具调用结果:外部 API 返回的大段 JSON 或调试日志。
- 历史推理链:智能体之前的思考过程、决定。
- 检索到的知识:从向量数据库或长期存储系统中拉取的记忆片段。
- 动态工作状态:比如由智能体自己维护的
NOTES.md或任务进度表。
推理时的上下文包括系统提示和行为指令、工具定义和模式、之前若干轮的交互历史、当前轨迹中的工具调用结果、检索到的文档或记忆,以及任何动态注入的工作状态。所有这些都在争夺同一个有限的注意力预算。Context Engineering 意味着在每一步对每个组件做出明确的选择,而不是让它们无节制地累积。
 引用 https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
引用 https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
3. 短期-活跃上下文窗口
短期上下文管理控制模型在单次推理步骤中看到的内容,这些对模型行为有最直接的影响。
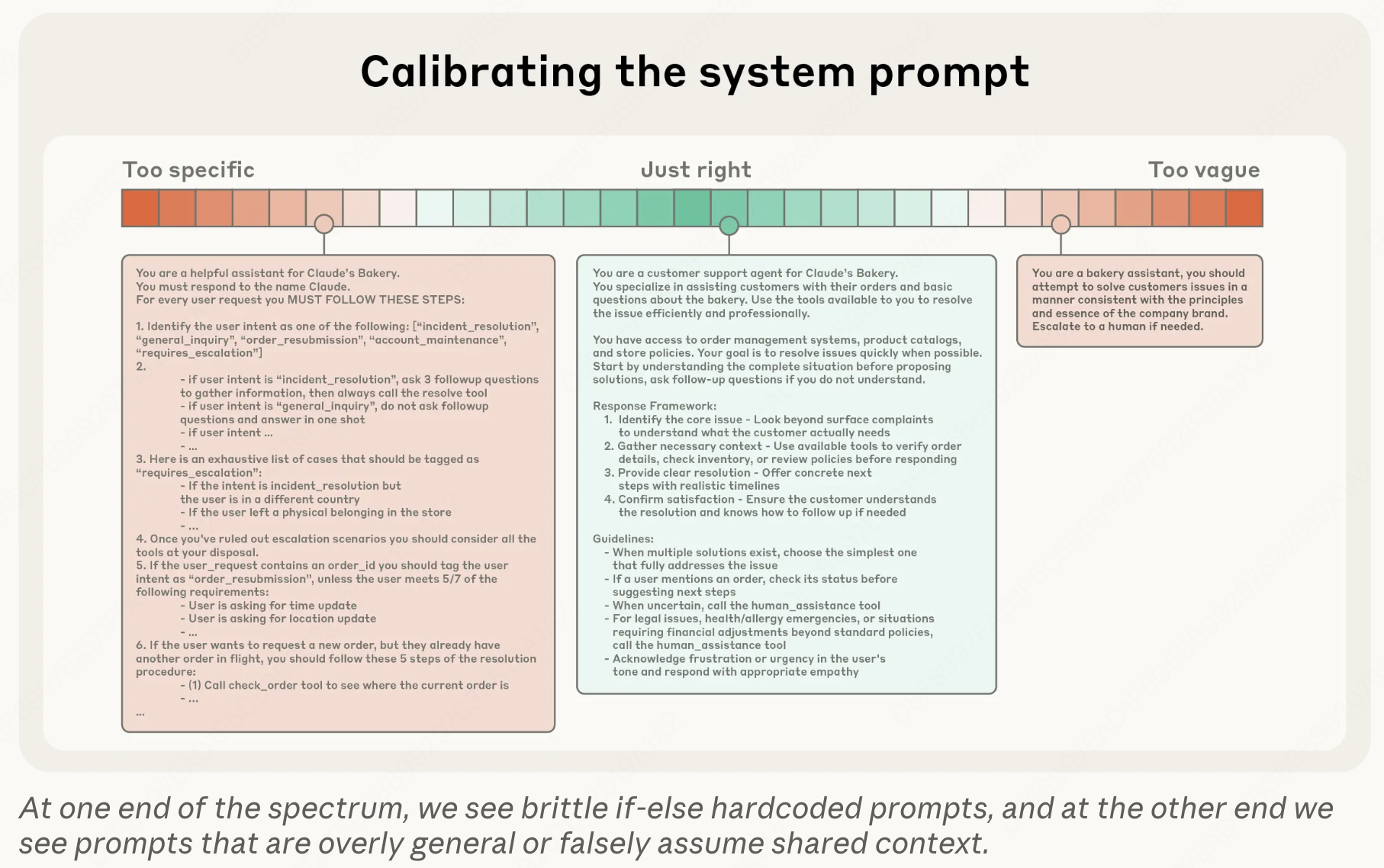
系统提示校准(System prompt calibration)。System Prompt 确立了 Agent 的行为边界,并在每次调用时消耗固定的预算。设计一个好的 System Prompt 的最大挑战在于找到合适的抽象层级:过于具体的 Prompt 会引入脆弱、维护负担重的逻辑,过于模糊的 Prompt 则使模型缺乏具体指导。在实践中,有效的 Prompt 被组织成清晰的章节,包括背景、指令、工具引导和输出格式,使用 XML 标签或 Markdown 标题进行分隔。推荐的工作流程是:从最佳可用模型上的最小提示开始,通过实验识别失效模式,然后添加针对性的指令以解决特定缺口。若预先枚举每一个边缘情况,往往会使提示膨胀,而不会提高可靠性。
 引用 https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
引用 https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
Token 高效化的工具设计(Token-efficient tool design)。工具定义是上下文的主要消耗者,每个模式、名称、描述和参数类型都会在每次调用时注入。一个大型工具集可能消耗数万个 token。从生产部署中涌现的原则是:优先选择更少、更具表达力的工具,而非大量细粒度的工具。如果人类工程师都无法判断在特定情境下应使用哪个工具,就不能指望模型做得更好。工具应该是自包含的、健壮的、用途明确的,参数名称应具有描述性,以发挥模型的优势。
即时检索与渐进式披露(Just-in-time retrieval and progressive disclosure)。与其预先加载所有可能相关的信息,有效的 Agent 会维护轻量级标识符,如文件路径、查询和网页链接,并在任务展开时按需加载数据。Anthropic 将这种方法称为渐进式披露。它反映了人类的工作方式——我们不会背诵整本语料,而是构建外部索引系统并按需检索。Claude Code 在实践中使用混合策略。CLAUDE.md 文件在会话开始时加载以提供项目上下文,而 glob 和 grep 命令让 Agent 导航并即时加载特定文件内容。这同时规避了陈旧索引问题,并降低了大规模预填充的成本。环境元数据也携带隐含信号。文件大小暗示复杂度;命名约定暗示用途;时间戳代理相关性。Agent 可以逐层建立理解,只在活跃窗口中保留当前必要的内容。
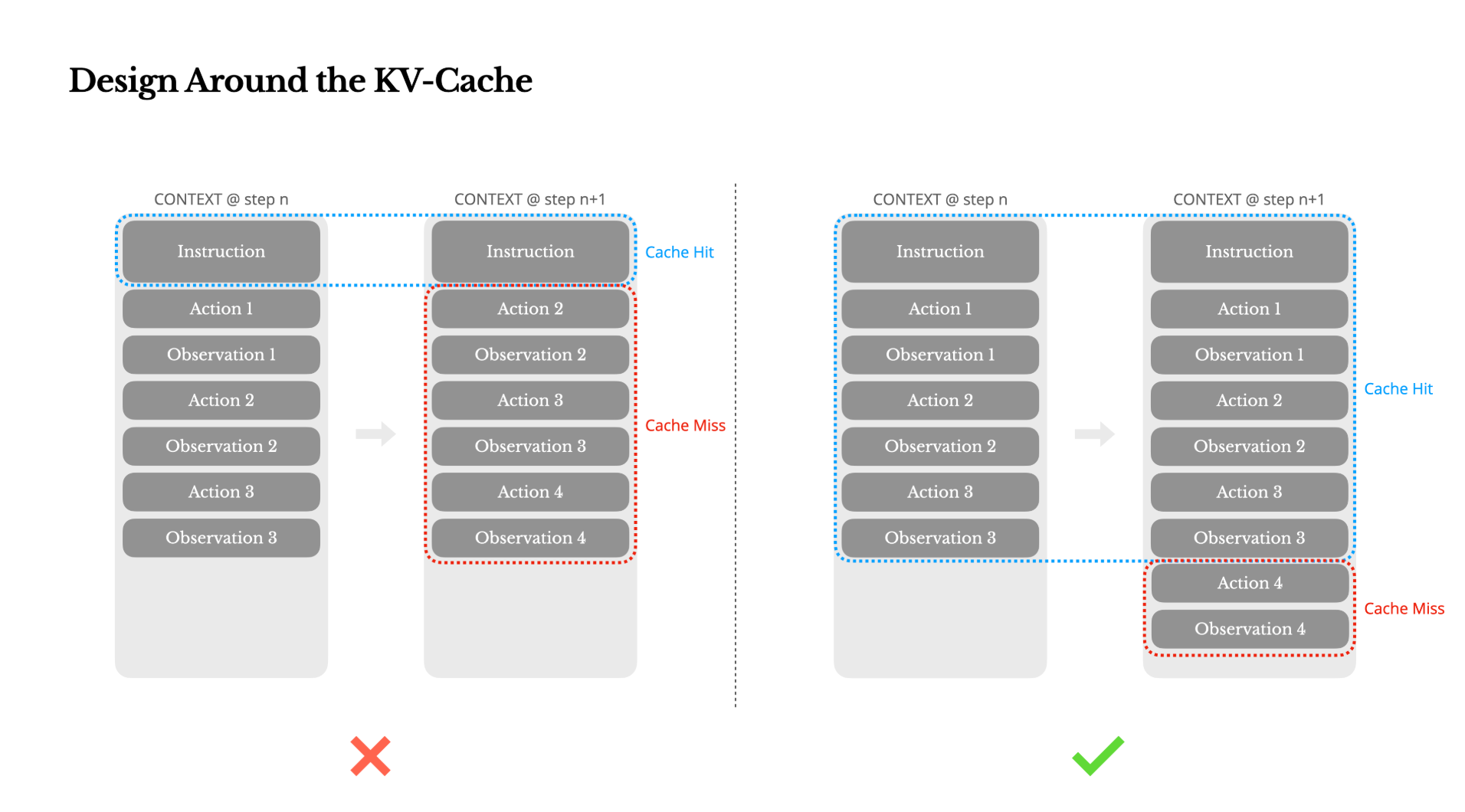
KV-cache 感知的上下文设计(KV-cache-aware context design)。Prompt cache 是性价比最高的单一优化,其收益完全取决于上下文的结构方式。Manus 团队在其博客 Context Engineering for AI Agents: Lessons from Building Manus 中将 KV-cache 命中率确定为”生产阶段 AI Agent 最重要的单一指标”,指出在 Claude Sonnet 上缓存的 token 成本为 $0.30/MTok,而未缓存的 token 为 $3.00/MTok。由此得出三条设计规则,第一,保持Prompt前缀稳定:系统提示开头的一个 token 差异就会使后续所有内容的缓存失效;第二,上下文设置为append-only模式:修改过去的动作或观察会破坏缓存重用,因为它修改了Prompt的前缀序列;第三,使用确定性序列化:JSON 序列化中不稳定的键序会在其他完全相同的请求中静默地使缓存失效。
 引用 https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
引用 https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
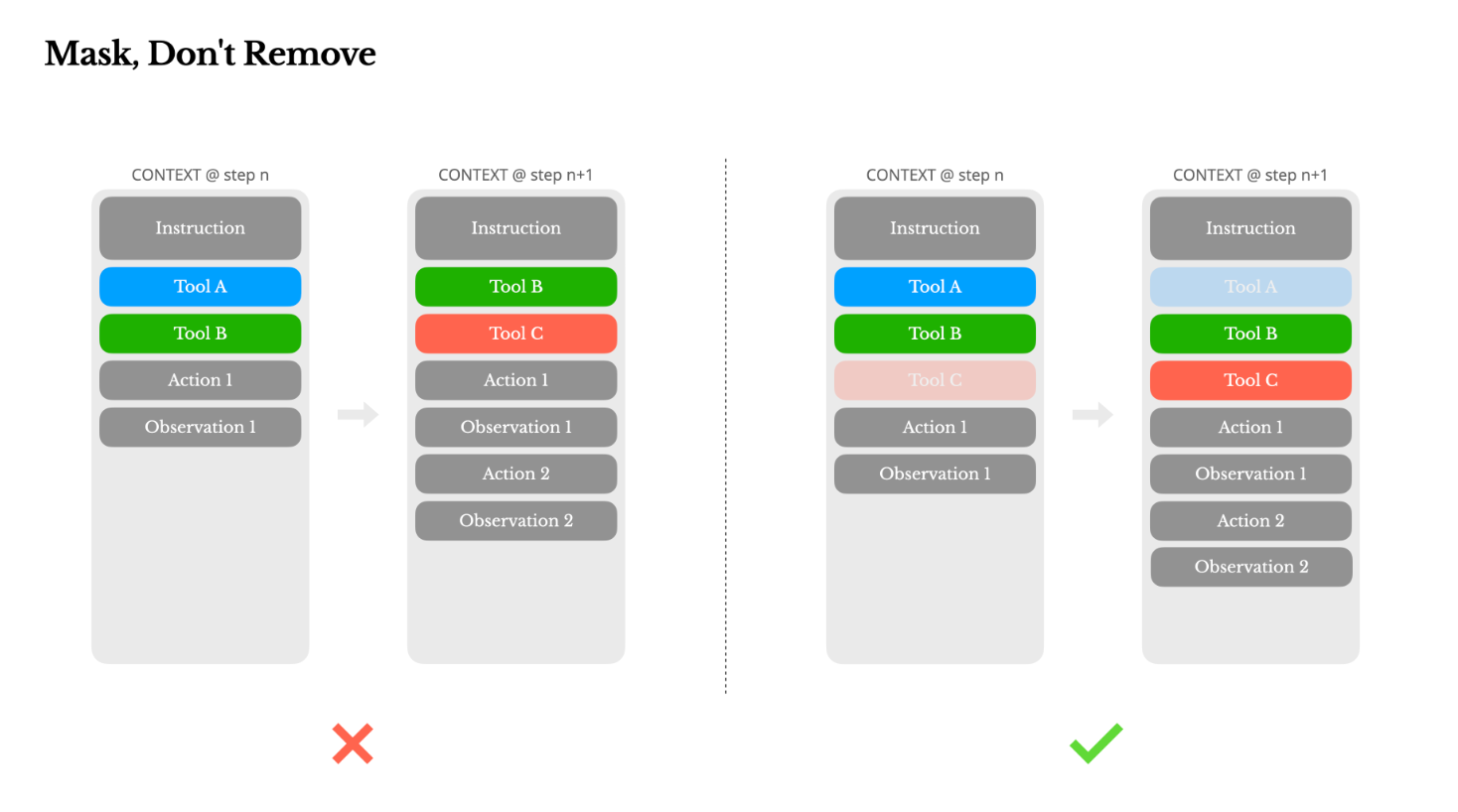
由于工具定义通常位于上下文的前部(紧随系统提示词之后),添加或移除工具会使后续所有轮次的缓存内容失效。Manus 团队采用“Token Logit Masking”的方式来管理工具,而不是动态的删除或修改工具定义。如何理解“Token Logit Masking”?本质上,这是一种约束模型生成内容的技术。简单来说,LLM 在预测下一个 Token 时,会对词表里的所有词给出一个概率分数(这个分数就是 Logit)。Logit 掩码就是人工将某些词的分数降为极低,从而让模型“没得选”,只能从剩下的词里挑选。具体地,Manus 并没有通过复杂的底层代码去修改模型的分数,而是利用了一个更巧妙、更通用的技术:响应前缀填充(Response Prefill)。这种技术允许在不改变工具定义的情况下约束动作空间,博客中提到了三种模式,包括:
- Auto: 仅填充回复前缀(如
<|im_start|>assistant),由模型自行决定是否调用工具。 - Required: 强制模型调用工具,但不限制具体哪一个。
- Specified: 强制模型从特定的子集中选择工具。例如,通过预填前缀
<|im_start|>assistant<tool_call>{"name": "browser_,可以强制模型只能选择浏览器相关的工具。
引用 https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
具体的实现例子
假设 Manus 的系统中定义了 100 个工具,其中既有浏览器工具(如
browser_search),也有命令行工具(如shell_exec)。场景:用户刚刚输入了一个网址,现在系统状态机判断 Agent 只能进行“浏览器操作”。
- 如果不做屏蔽: 模型可能会在上下文里搜寻那 100 个工具,有时会犯错,跳出浏览器去执行一个
shell_exec命令。- 利用“前缀填充”实现屏蔽: 当系统向 LLM 请求下一步动作时,它不会只发一段对话引导,而是提前替模型写好一部分开头,如
<|im_start|>assistant<tool_call>{"name": "browser_- 屏蔽的效果:由于模型是按照“预测下一个 Token”的方式工作的,现在它看到的最新内容是
"browser_。在模型的逻辑里,它必须补全这个字符串。这时,所有不以browser_开头的工具(比如所有的shell_工具)在这一时刻的生成概率就变成了 0。模型被强行限制在了“浏览器工具”这个子集里,它只能接着写出search"、click"或scroll"。
Anthropic 的上下文管理 通过显式的 cache_control 断点将 Prompt Cache 技术转化成一种简单可控的产品功能,不再让开发者被动地依赖模型的缓存机制。(注:具体是怎么用这个 cache_control 的?详见https://platform.claude.com/docs/en/build-with-claude/prompt-caching、 https://github.com/shareAI-lab/mini-claude-code/blob/main/articles/上下文缓存经济学.md)
|
|
4. 中期-状态持久化
中期上下文管理解决的是活跃上下文窗口与长期记忆系统之间的鸿沟。这一层级的管理核心在于状态的持久化与恢复,即如何让智能体在跨多个回合运行或任务重置时,不丢失已积累的进度,保持逻辑的一致性。
论文总结了目前工业界和研究界最有效的几种中期持久化手段:
- 结构化笔记 (Structured Note-Taking):
- 做法:智能体维护一个持久化的笔记文件(如 NOTES.md 或 todo.md)。在每次运行开始时读取,结束前更新。
- 案例分析:Anthropic 观察到智能体在玩数千步的《宝可梦》游戏时,通过自发记录地图、战斗策略和任务目标,即便在会话历史被清除后,依然能保持长达数小时的逻辑连贯性。这本质上是将工作记忆“外挂”到了磁盘上。
- 基于文件的规划 (File-based Planning):
- 进阶手段:将完整的规划(如依赖图、中间结果、规格说明)直接写入文件系统。
- 优势:通过按需加载当前步骤所需的特定文件片段,智能体可以完全绕过上下文窗口的限制,处理对当前步骤不直接相关的海量数据。
- 跨运行注入 (Cross-run Injection):
- 做法:捕获前一次运行的重要输出,并将其作为下一次会话的起始背景。
- 工具实例:claude-mem 等插件层通过提取最有用的信息块,实现在无需向量数据库的情况下提供跨运行的连续性。
5. 长期-持久记忆系统
长期持久化记忆系统是上下文管理层中覆盖时间跨度最长、架构最复杂的子层。与中期管理依赖简单的摘要前向注入不同,长期记忆系统提供了索引化、可检索的存储,能够跨越不同的会话、不同的任务甚至不同的智能体实例实现任意维度的记忆召回。
长期记忆系统的设计灵感主要源自计算机操作系统的虚拟内存机制。论文引用了 MemGPT 的核心理念,即由于注意力机制的物理限制,应将 LLM 的上下文窗口视为 RAM,而将外部持久化存储视为磁盘。通过提供“分页(Paging)”功能的工具调用,模型可以主动将不再需要的信息换出到磁盘,并在需要时精准召回。
长期记忆系统的整体架构如下图所示,通常包括四个关键组件,即信息提取、记忆管理、记忆存储和信息检索。智能体系统通过四个关键组件协同运作:
- 信息提取。该组件描述智能体系统如何识别并从当前的用户消息 M 中提取对更新记忆有用的关键信息。它过滤掉冗余细节,并将相关内容转化为适合下游处理的不同类型知识(例如从文本中导出的三元组、信息摘要)。
- 记忆管理。该组件展示智能体系统如何通过整合、更新、过滤和增强等操作,将新提取的信息与现有记忆 H 融合。目标是维护一个连贯、一致且最新的记忆状态,能准确反映积累的知识。
- 记忆存储。该组件规定智能体系统如何组织和持久化处理后的记忆。它可以采用向量存储、图存储或混合存储格式,以满足多样化的信息检索需求。
- 信息检索。当新查询到达时,该组件控制智能体系统如何从记忆库中检索最相关的信息以支持推理。
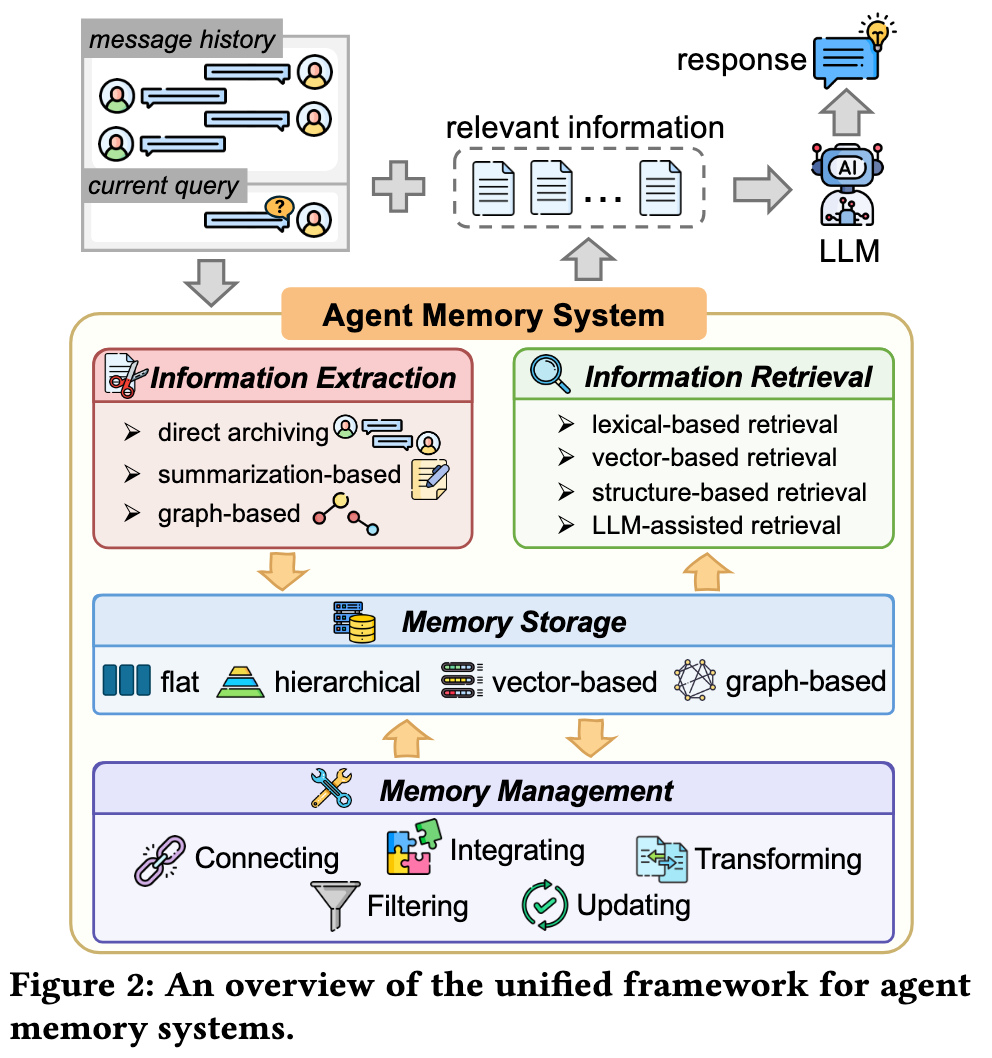 引用 https://arxiv.org/abs/2604.01707
引用 https://arxiv.org/abs/2604.01707
6. 如何解决长程任务的上下文管理
当任务跨度达到数百轮时,单一的时间尺度管理(如短期的活动窗口或长期的记忆检索)已不足以维持智能体的稳定性。本节讨论的就是如何使智能体在 100+ 轮交互中保持连贯性。这是整个上下文层级的集成性挑战。
从上下文管理的视角,解决长程任务的核心手段有压缩、隔离与重置。
上下文压缩(context compaction)。压缩指的是当上下文窗口接近极限时,系统会生成当前状态的压缩表示并重新启动执行。Anthropic博客表示摘要必须保留架构决策、未解决的缺陷和实现细节,同时丢弃冗余的工具输出和已整合的中间推理。
Sub-Agent 上下文隔离(sub-agent context isolation)。当任务需要深入探索子主题时,探索本身会产生大量在子任务内有用的中间上下文,但会污染主编排器(即,主Agent)对整体任务的视图。该架构通过将子任务分配给专用的子Agent来解决这一问题,每个子Agent拥有全新的上下文窗口,只向编排器返回摘要,具体的探索上下文被隔离在子 Agent 内部,编排器只接收提炼后的结果。
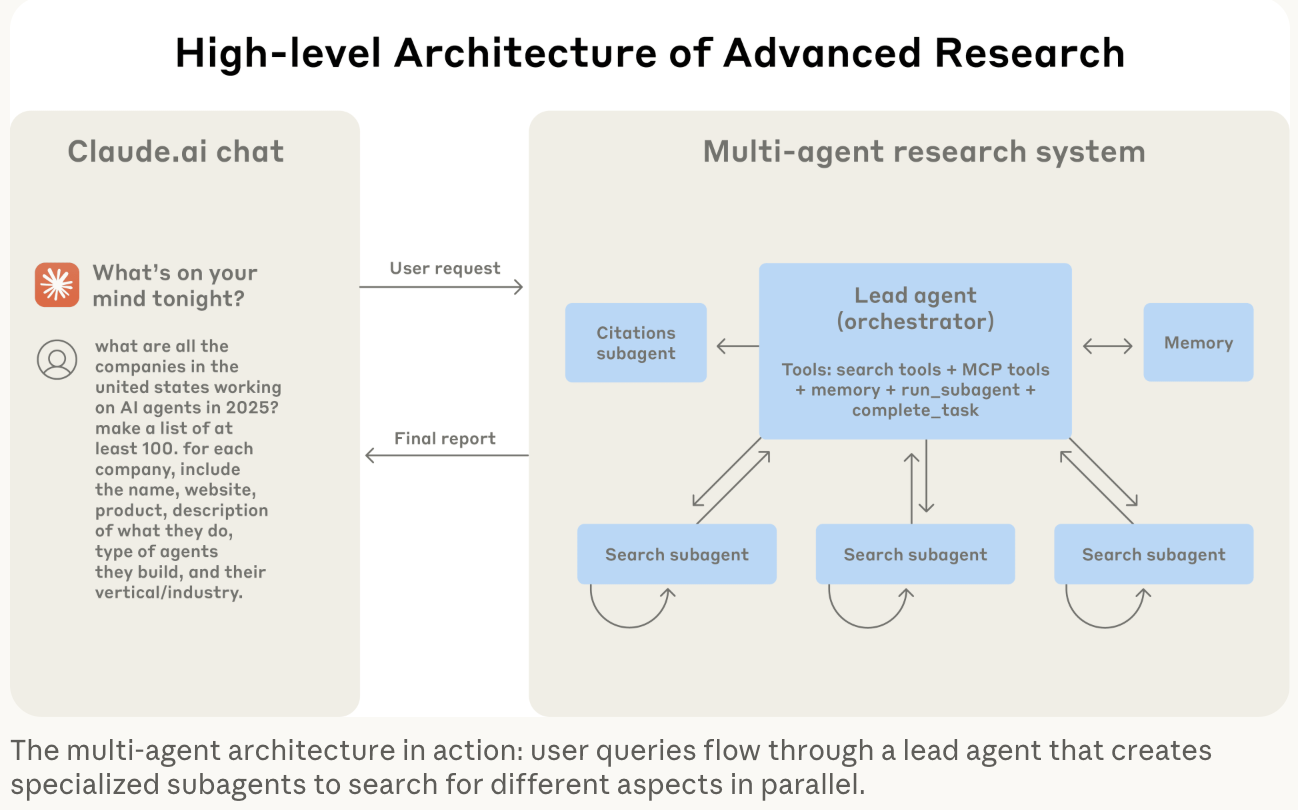 引用 https://www.anthropic.com/engineering/multi-agent-research-system
引用 https://www.anthropic.com/engineering/multi-agent-research-system
上下文重置 (Context Reset)。Anthropic 的工程实践提供了一个比“压缩”更激进的手段——重置。上下文重置是指完全清空模型的上下文窗口,并启动一个全新的智能体实例。它不同于简单的对话截断或压缩,而是通过一种“Structured Handoff(结构化移交)”机制,将前一个智能体的最终状态和后续步骤传递给新智能体,从而实现任务的持续推进。为什么要引入上下文重置?博客指出,传统的长对话处理方式(即让一个智能体持续运行)在处理复杂任务时会遇到两个主要故障模式:
- 连贯性丧失(Loss of Coherence):随着上下文窗口逐渐填满,模型在处理长任务时往往会失去逻辑的连贯性。
- 上下文焦虑(Context Anxiety):这是Anthropic提出的一个重要观察。某些模型(如 Claude Sonnet 4.5)在接近其上下文极限时,会因为“感知”到空间不足而开始表现出紧迫感,从而过早地收尾工作,导致任务完成质量下降。
上下文重置 vs. 上下文压缩
- 上下文压缩:对对话的早期部分进行原地总结(Summarize in place),以便同一个智能体能在缩短后的历史记录中继续工作。这种方式的优点是保持了连续性,但由于没有提供“白板”状态,无法消除模型的“上下文焦虑”。
- 上下文重置:直接提供一个纯净的起点(Clean Slate)。这彻底解决了焦虑问题,但对“Handoff”的质量要求极高,必须包含足够的状态信息让下一个智能体无缝接手。
到了实际的生产环境中,往往不会仅应用单一的技术,而是采用混合决策模式,根据任务结构在执行的不同阶段选择不同技术。Anthropic 将该框架刻画为:
- 预加载始终需要的内容;
- 即时检索条件需要的内容;
- 在窗口接近饱和时压缩历史;
- 处理会产生大量噪音的深度探索任务或可并行任务时,生成子 Agent。
此外,Anthropic 还补充了 Harness 层面的视角:检查点与恢复(checkpoint and resume)模式允许 Agent 在遭遇瞬态故障时不丢失任务状态,生命周期钩子(lifecycle hooks)可以在达到阈值时自动触发压缩或记忆整合。总而言之,上下文管理应该 Harness 层的工作,而非业务的工作。
7. 上下文漂移与当前方法的局限
本节探讨上下文漂移(Context Drift)以及当前技术在解决长程任务时的根本局限性。如果说“上下文腐化”是关于单次推理的质量问题,那么“上下文漂移”则是关于整个任务轨迹的连贯性危机。
1、什么是“上下文漂移”?上下文漂移被定义为执行轨迹的一种属性。它描述的是随着智能体与环境交互轮数的增加,其行为逐渐偏离原始意图的现象。
上下文腐化 vs. 上下文漂移
- 上下文腐化 (Context Rot):发生在单步推理中。Token 越多,模型定位和推理信息的能力越差。这是一种“瞬间”的失效。
- 上下文漂移 (Context Drift):发生在长序列中。即使单步推理质量尚可,但多步累积的微小误差会导致智能体在 100 轮之后开始重复工作、自相矛盾,甚至完全忘记最初的目标。
2、为什么当前技术无法根治漂移?论文指出,目前主流的上下文管理手段在长程任务面前都存在“天花板”:
- 压缩的局限:压缩本质上是有损的。每一次压缩都会删减细节,虽然短期内节省了 Token,但损失的信息是不可恢复的。这些微小的、被删除的约束条件会随时间累积,形成巨大的认知缺口。
- 检索的局限:检索依赖于query的质量。如果智能体已经开始漂移,它可能根本不知道自己遗忘了什么,从而无法构造出正确的查询词来找回关键记忆。这就是所谓的“不知道自己不知道”。
- 隔离的局限:子Agent虽然能保护主Agent的窗口不被细节噪音污染,但无法阻止主Agent自身由于长期运行而产生的逻辑疲劳。
3、为什么漂移难以被发现?论文提出了一个深刻的工程观察:目前的基准测试大多太短了,因此存在评估盲点。像 SWE-bench 这样的标准测试通常在几十步内就结束了,这个长度还不足以触发严重的上下文漂移。为了解决这一问题,研究界开始推出针对性更强的工具,如 MemBench(测试跨会话推理)、MemoryArena(测试多会话相互依赖任务)以及专门隔离记忆质量与生成质量的增量评估法。
4、基于以上的分析,得出本节最核心的结论是,即仅靠上下文工程无法解决长程任务的可靠性问题。因此,有必要从 Context Engineering 转向 Harness Engineering。当智能体在 100 轮之后开始胡言乱语时,必须引入 ETCLOVG 架构中的其他层级进行协作,包括:
- 验证层:引入外部验证循环,检测智能体的当前状态是否与真实物理环境(如文件系统、数据库)发生了背离。
- 治理层:在关键节点设置 human-in-the-loop checkpoint。由于模型存在“上下文焦虑”,需要人类在关键节点进行校准。
- 观测层:通过异常检测识别行为发散的早期信号,在漂移不可逆转之前强制触发上下文重置,提供一个“干净的底座”。